Let's suppose we have a dataframe that be generated using this code:
import pandas as pd
d = {'p1': np.random.rand(32),
'a1': np.random.rand(32),
'phase': [0,0,0,0, 1,1,1,1, 2,2,2,2, 3,3,3,3, 0,0,0,0, 1,1,1,1, 2,2,2,2, 3,3,3,3],
'file_number': [1,1,1,1, 1,1,1,1, 1,1,1,1, 1,1,1,1, 2,2,2,2, 2,2,2,2, 2,2,2,2, 2,2,2,2]
}
df = pd.DataFrame(d)
For each file number i want to take only last N rows of phase number 3. So that the result for N==2 looks like this:
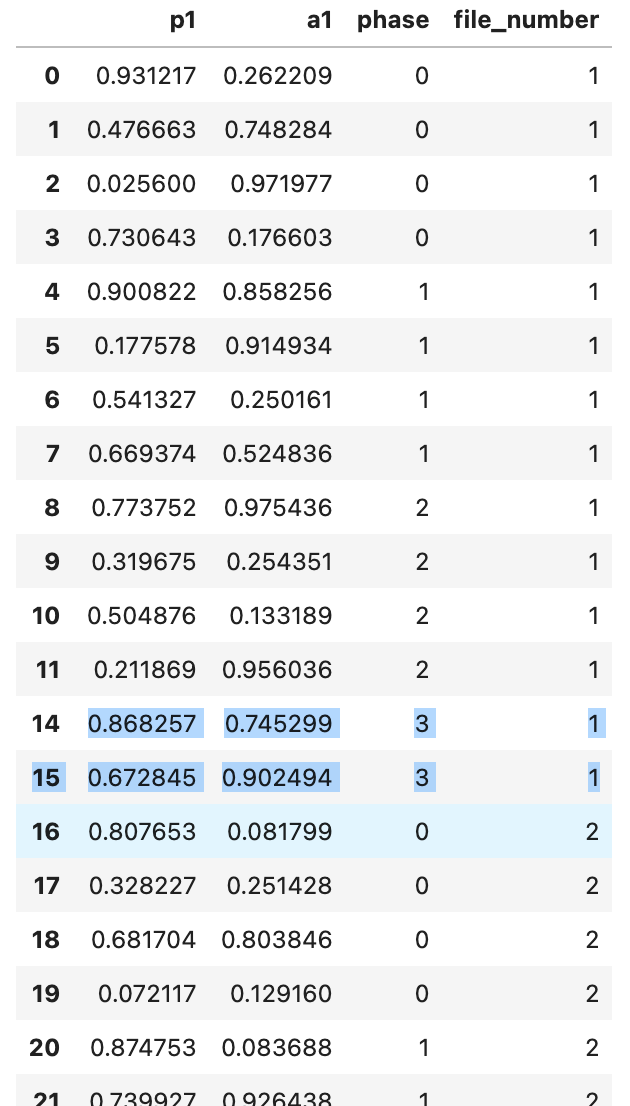
Currently I'm doing it in this way:
def phase_3_last_n_observations(df, n):
result = []
for fn in df['file_number'].unique():
file_df = df[df['file_number']==fn]
for phase in [0,1,2,3]:
phase_df = file_df[file_df['phase']==phase]
if phase == 3:
phase_df = phase_df[-n:]
result.append(phase_df)
df = pd.concat(result, axis=0)
return df
phase_3_last_n_observations(df, 2)
However, it is very slow and I have terabytes of data, so I need to worry about performance. Does anyone have any idea how to speed my solution up? Thanks!
CodePudding user response:
I use idea from deleted answer - get indices by previous rows for rows matching 3 by GroupBy.cumcount and remove them by DataFrame.drop:
def phase_3_last_n_observations(df, N):
df1 = df[df['phase'].eq(3)]
idx = df1[df1.groupby('file_number').cumcount(ascending=False).ge(N)].index
return df.drop(idx)
#index is reseted for default, because used for remove rows
df = phase_3_last_n_observations(df.reset_index(drop=True), 2)
CodePudding user response:
Filter the rows where phase is 3 then groupby and use tail to select the last two rows per file_number, finally append to get the result
m = df['phase'].eq(3)
df[~m].append(df[m].groupby('file_number').tail(2)).sort_index()
p1 a1 phase file_number
0 0.223906 0.164288 0 1
1 0.214081 0.748598 0 1
2 0.567702 0.226143 0 1
3 0.695458 0.567288 0 1
4 0.760710 0.127880 1 1
5 0.592913 0.397473 1 1
6 0.721191 0.572320 1 1
7 0.047981 0.153484 1 1
8 0.598202 0.203754 2 1
9 0.296797 0.614071 2 1
10 0.961616 0.105837 2 1
11 0.237614 0.640263 2 1
14 0.500415 0.220355 3 1
15 0.968630 0.351404 3 1
16 0.065283 0.595144 0 2
17 0.308802 0.164214 0 2
18 0.668811 0.826478 0 2
19 0.888497 0.186267 0 2
20 0.199129 0.241900 1 2
21 0.345185 0.220940 1 2
22 0.389895 0.761068 1 2
23 0.343100 0.582458 1 2
24 0.182792 0.245551 2 2
25 0.503181 0.894517 2 2
26 0.144294 0.351350 2 2
27 0.157116 0.847499 2 2
30 0.194274 0.143037 3 2
31 0.542183 0.060485 3 2
CodePudding user response:
As an alternative solution to what already exists: You can calculate the last elements for all phase groups and afterwards just use .loc to get the needed group result. I have written the code for N==2, if you want for N==3, then use [-1, -2, -3]
result = df.groupby(['phase']).nth([-1, -2])
PHASE = 3
result.loc[PHASE]