(* This might be a duplicated question, but it would be surprising if we don't have this feature yet. *)
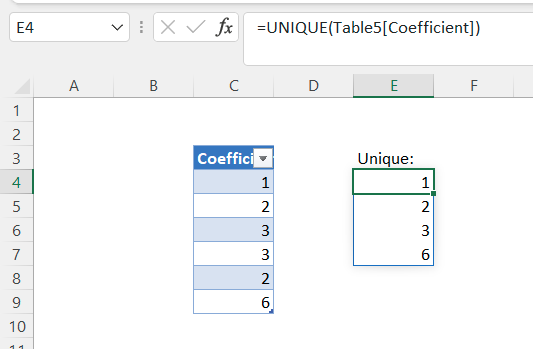
I have a table Table5 in Column C, whose height may change. in Column E, I have a formula to e.g., extract unique values, thus the resulting spilled range has a dynamic height.
I would like to make a conditional formatting over the resulting spilled range, for instance, highlight the value which is greater than 5.
But I didn't find how to define a conditional formatting rule over a spilled range (e.g., by using #). I don't want to apply the conditional formatting rule over the whole column.
Does anyone know how to achieve this?
CodePudding user response:
The only way I could think of was:
=AND(ROW($E1)>=4,ROW($E1)<=COUNTA(UNIQUE(INDIRECT("Table5[Coefficient]"))) 4,$E1>5)
Use the above formula as a conditional formatting rule on the whole of column E:E.
CodePudding user response:
You could set a conditional formatting rule over the whole column, but use some additional logic to ensure it only applies to the range you want, ie:
=AND(ROW(E1)>=4, ROW(E1)<=4 COUNT(UNIQUE(INDIRECT("Table5[Coefficient]"))), [your condition here])
Apply the rule to E:E and it will only evaluate to True for rows in the range you want.
CodePudding user response:
An alternate workaround is to use a named range which will accept the spill range # assignation.
Assign Named Range "CF_1" as:
=OFFSET($E$4,0,0,COUNTA($E$4#))
The conditional formatting to be applied to E:E can then be:
=AND(ROW(E1)=MEDIAN(ROW(E1),MIN(ROW(CF_1)),MAX(ROW(CF_1))),E1>5)
In essence, this isn't too much different to the answers by JvdV and Professor Pantsless as it kind of boils down to the same thing, but it does have the bonus that it will only apply to only the rows of the spill range (the cells E1-E3 haven't been taken into account yet for the other answers to date).
UPDATE
And in fact, you don't have to use a named range at all as this code will also accept # (still can't work out how to apply over only the spill range though)
=AND(ROW(E1)=MEDIAN(ROW(E1),MIN(ROW(E$4#)),MAX(ROW(E$4#))),E1>5)
CodePudding user response:
I've been using several different conditional formats applied to the entire column, or group of columns. The table looks like this:

The following formulas are conditional formatting applied to the entire row/rows, not individual cells:
Header:
=AND(OR(ISERR(OFFSET(A1,-1,0)),ISBLANK(OFFSET(A1,-1,0)))=TRUE,ISBLANK(A1)=FALSE)
Band:
=AND(CELL("row",A1)=EVEN(CELL("row",A1)),ISBLANK(A1)=FALSE)
Last row (or total row):
=AND(ISBLANK(A1)=FALSE,ISBLANK(A2)=TRUE)
With the following formatting:

If you do not want this formatting to be applied to non-spill cells, you can determine if a cell was spilled or directly input. You can do this with a formula or write a UDF.
Using a formula you need to fake it. You can use ISFORMULA to find where the spill formula was entered, and NOT(ISBLANK()) to identify spilled rows. You would then have to assume a formula followed by non-blank, non-formula cells is a spilled formula. Helper columns may be helpful.
Using a UDF, you can directly determine if a cell is spilled. Below is a basic example. You can add more checking to determine if the formula is actually spilled if desired.
Public Function isFormulaOrSpill(ByVal rRange As Range) As Boolean
Dim this_bIsSpill As Boolean
Dim this_bIsFormula As Boolean
this_bIsSpill = rRange.HasSpill
this_bIsFormula = rRange.HasFormula
isFormulaOrSpill = (this_bIsSpill Or this_bIsFormula)
End Function
Recently I've been building entire tables as spilled ranges (including header and total rows). Here is an example of those who want to give it a shot:
=LET(
Column_Key, Table_Status[System],
Column_FtEstimated, Table_Status[Estimated],
Column_FtModeled, IF(Table_Status[Modeled]>Table_Status[Estimated],Table_Status[Estimated],Table_Status[Modeled]),
Categories, SORT(UNIQUE(Column_Key)),
Array_BoolKey, (TRANSPOSE(Column_Key)=Categories) 0,
Mask1, TRANSPOSE(ISNUMBER(XMATCH(Column_Filter1,List_Filter1))),
Mask2, TRANSPOSE(ISNUMBER(XMATCH(Column_Filter2,List_Filter2))),
Array_BoolMasked, Array_BoolKey,
Masked_FtModeled, IFERROR(Array_BoolMasked*TRANSPOSE(Column_FtModeled),0),
Masked_FtEstimated, IFERROR(Array_BoolMasked*TRANSPOSE(Column_FtEstimated),0),
Array_Ones, SEQUENCE(COLUMNS(Array_BoolMasked),1,1,0),
Body_Count_Lines, MMULT(Array_BoolKey, Array_Ones),
Body_Sum_FtModeled, MMULT(Masked_FtModeled, Array_Ones),
Body_Sum_FtEstimated, MMULT(Masked_FtEstimated, Array_Ones),
Body_Percent_FtModeled, IFERROR(Body_Sum_FtModeled/Body_Sum_FtEstimated,"-"),
Total_Count_Lines, IFERROR(SUM(Body_Count_Lines),"-"),
Total_Sum_FtModeled, IFERROR(SUM(Body_Sum_FtModeled),"-"),
Total_Sum_FtEstimated, IFERROR(SUM(Body_Sum_FtEstimated),"-"),
Total_Percent_FtModeled, IFERROR(Total_Sum_FtModeled/Total_Sum_FtEstimated,"-"),
Array_Seq, {1,2,3,4,5},
Array_Header, CHOOSE( Array_Seq, "System", "Lines", "Modeled Feet", "Estimated Feet", "Percent Modeled"),
Array_Body, CHOOSE( Array_Seq, Categories, Body_Count_Lines, Body_Sum_FtModeled, Body_Sum_FtEstimated, Body_Percent_FtModeled),
Array_Total, CHOOSE( Array_Seq, "Total", Total_Count_Lines, Total_Sum_FtModeled, Total_Sum_FtEstimated, Total_Percent_FtModeled),
Range1,Array_Header,
Range2,Array_Body,
Range3,Array_Total,
Rows1,ROWS(Range1), Rows2,ROWS(Range2), Rows3,ROWS(Range3), Cols1,COLUMNS(Range1),
RowIndex, SEQUENCE(Rows1 Rows2 Rows3), ColIndex,SEQUENCE(1, Cols1),
RangeTable,IF(
RowIndex<=Rows1,
INDEX(Range1,RowIndex,ColIndex),
IF(RowIndex<=Rows1 Rows2,
INDEX(Range2,RowIndex-Rows1,ColIndex),
INDEX(Range3,RowIndex-Rows1-Rows2,ColIndex)
)),
Return, RangeTable,
Return
)