I have a sample table with following structure and data.
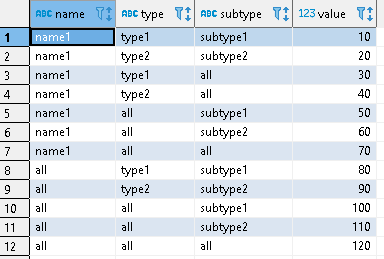
I have to select value from this table with respect to the name, type and subtype. If any one of the column value is not matching the condition then value with 'all' should be picked. Below is the query created. declare name varchar default 'name1' declare type varchar default 'type1' declare subtype varchar default 'subtype1'
SELECT * FROM sampledata sd
where
case when (exists(select 1 from sampledata where name = :name))
then sd.name = :name and
case when exists (select 1 from sampledata where name = :name and type = :type)
then sd.type = :type and
case when exists (select 1 from sampledata where name = :name and type = :type and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
else sd.type = 'all' and
case when exists (select 1 from sampledata where name = :name and type = 'all' and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
end
else sd.name = 'all' and
case when exists (select 1 from sampledata where name = 'all' and type = :type)
then sd.type = :type and
case when exists (select 1 from sampledata where name = 'all' and type = :type and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
else sd.type = 'all' and
case when exists (select 1 from sampledata where name = 'all' and type = 'all' and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
end
end
This is the result for 'name1', 'type1' and 'subtype1'.

This is the result for 'name3', 'type3' and 'subtype1' parameters.

CREATE TABLE sampledata (
"name" varchar NULL,
"type" varchar NULL,
subtype varchar NULL,
value float4 NULL
);
INSERT INTO sampledata
("name", "type", subtype, value)
VALUES ('name1', 'type1', 'subtype1', 10),
('name1', 'type2', 'subtype2', 20),
('name1', 'type1', 'all', 30),
('name1', 'type2', 'all', 40),
('name1', 'all', 'subtype1', 50),
('name1', 'all', 'subtype2', 60),
('name1', 'all', 'all', 70),
('all', 'type1', 'subtype1', 80),
('all', 'type2', 'subtype2', 90),
('all', 'all', 'subtype1', 100),
('all', 'all', 'subtype2', 110),
('all', 'all', 'all', 120);
The query is working fine and I would like to know if there an optimized logic without using the nested case to achieve the same result.
Thanks in advance.
CodePudding user response:
I would suggest the following approach :
WITH list AS
( SELECT name, type, subtype
, case when name = 'all' then 2 else 1 end AS name_weight
, case when type= 'all' then 2 else 1 end AS type_weight
, case when subtype= 'all' then 2 else 1 end AS subtype_weight
FROM sampledata sd
WHERE (name = 'name3' OR name = 'all')
AND (type = 'type3' OR type = 'all')
AND (subtype = 'subtype1' OR subtype = 'all')
)
SELECT name, type, subtype
FROM list
ORDER BY (name_weight*type_weight*subtype_weight) ASC
LIMIT 1
Then this query will return a random result if both rows exist in the table :
(all, type3,subtype1) and (name3,all,subtype1)
because they will get the same weight = name_weight*type_weight*subtype_weight, so the ORDER BY clause must be refined for this kind of case, for example by defining different weights for name, type, subtype so that to prioritize their importance
CodePudding user response:
Enumerate and order:
\i tmp.sql
-- The table definition
-- ---------------------------------
CREATE TABLE sampledata
( id serial primary key
, name text
, type text
, subtype text
, val integer
);
-- I had to type in the data myself
-- ---------------------------------
INSERT INTO sampledata ( name , type , subtype ,val)
VALUES ('name1' , 'type1' , 'subtype1', 10)
, ('name1' , 'type2' , 'subtype2', 20)
, ('name1' , 'type1' , 'all', 30)
, ('name1' , 'type2' , 'all', 40)
, ('name1' , 'all' , 'subtype1', 50)
, ('name1' , 'all' , 'subtype2', 60)
, ('name1' , 'all' , 'all', 70)
, ('all' , 'type1' , 'subtype1', 80)
, ('all' , 'type2' , 'subtype2', 90)
, ('all' , 'all' , 'subtype1', 100)
, ('all' , 'all' , 'subtype2', 110)
, ('all' , 'all' , 'all', 120)
;
SELECT * FROM sampledata ;
-- Prepared query to allow parameters
-- ------------------------------------
PREPARE omg(text,text,text) AS
SELECT *
, 0::int
40*(name = $1)::int
20*(type = $2)::int
10*(subtype = $3)::int
4*(name = 'all' )::int
2*(type = 'all' )::int
1*(subtype = 'all' )::int
AS flag
FROM sampledata sd
WHERE name in($1, 'all' )
AND type in($2, 'all' )
AND subtype in($3, 'all' )
ORDER BY flag DESC
LIMIT 1
;
-- Example#1
-- -----------
EXECUTE omg('name1' , 'type1' , 'subtype1' );
-- Example#2
-- -----------
EXECUTE omg('name3' , 'type3' , 'subtype1' );
Results:
DROP SCHEMA
CREATE SCHEMA
SET
CREATE TABLE
INSERT 0 12
id | name | type | subtype | val
---- ------- ------- ---------- -----
1 | name1 | type1 | subtype1 | 10
2 | name1 | type2 | subtype2 | 20
3 | name1 | type1 | all | 30
4 | name1 | type2 | all | 40
5 | name1 | all | subtype1 | 50
6 | name1 | all | subtype2 | 60
7 | name1 | all | all | 70
8 | all | type1 | subtype1 | 80
9 | all | type2 | subtype2 | 90
10 | all | all | subtype1 | 100
11 | all | all | subtype2 | 110
12 | all | all | all | 120
(12 rows)
PREPARE
id | name | type | subtype | val | flag
---- ------- ------- ---------- ----- ------
1 | name1 | type1 | subtype1 | 10 | 70
(1 row)
id | name | type | subtype | val | flag
---- ------ ------ ---------- ----- ------
10 | all | all | subtype1 | 100 | 16
(1 row)