I am trying to make a simple Cuda application that creates integral image of given matrix. One of the steps I need to do, is to create integral image of every row. In order to do this, I want to assign 1 thread to each row. Function that is supposed to do this:
__global__ void IntegrateRows(const uchar* img, uchar* res)
{
int x = blockIdx.x * blockDim.x threadIdx.x;
int y = blockIdx.y * blockDim.y threadIdx.y;
if (x >= Width || y >= Height)
return;
int sum = 0;
int row = y * Width;
for (int i = 0; i < Width - x; i)
{
res[row i x] = sum img[row i x];
sum = img[row i x];
}
}
I use a matrix of size 3840x2160 filled with ones (cv::Mat::ones(Size(Width, Height), CV_8UC1)) for tests. When I try to print out content of the result, it always returns sequence of numbers from 1 to 255:
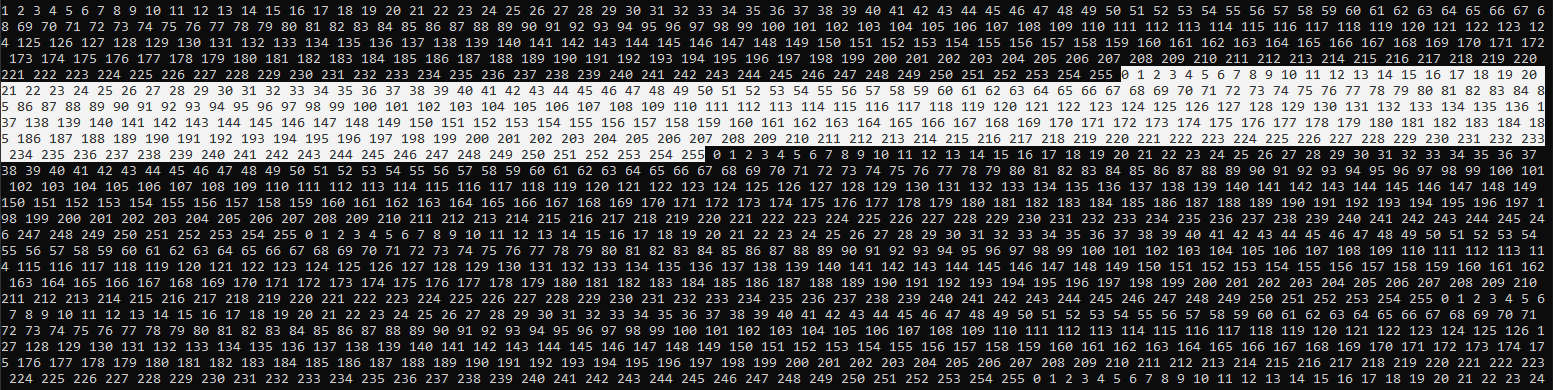
The execution configurations is:
dim3 threadsPerBlock(1, 256);
dim3 numBlocks(1, 16);
IntegrateRows<<<numBlocks, threadsPerBlock >>>(img, res);
My GPU is Nvidia RTX 3090.
CodePudding user response:
tl;dr: Make your output matrix have larger elements
If you integrate/prefix-sum the sequence
1, 1, 1, 1, ...
You get:
0, 1, 2, 3, ...
and this sequence will wrap around to 0 when you reach the maximum value of your element type. In your case, it's a uchar, i.e. unsigned char. And its maximum value is 255. Add another 1 to it, and you get 0. So: 0, 1, 2, 3, ... 253, 254, 255, 0, 1, ... and so on.
If you change the output matrix element type to unsigned short (or maybe simply unsigned int) - you won't get the wrap-around behavior. Of course, if you add up 255's instead of 1's, and/or your matrix is larger, then again the type's represented range might not be large enough.