how to convert row into a dimension under condition?
row 0, and row 3 are category total
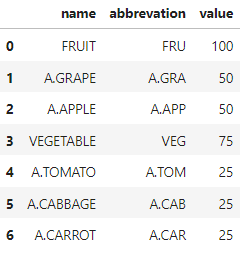
current format
import pandas as pd
data = [['FRUIT', 'FRU', 100],['A.GRAPE','A.GRA', 50],['A.APPLE','A.APP', 50],
['VEGETABLE', 'VEG', 75],['A.TOMATO','A.TOM', 25],['A.CABBAGE','A.CAB', 25],['A.CARROT','A.CAR', 25]]
df = pd.DataFrame(data, columns = ['name', 'abbrevation', 'value'])
df.head(10)
desired format
data2 = [['FRUIT','FRU','A.GRAPE','A.GRA', 50],['FRUIT','FRU','A.APPLE','A.APP', 50],
['VEGETABLE','VEG','A.TOMATO','A.TOM', 25],['VEGETABLE','VEG','A.CABBAGE','A.CAB', 25],['VEGETABLE','VEG','A.CARROT','A.CAR', 25]]
df2 = pd.DataFrame(data2, columns = ['category','category abbrevation','name', 'abbrevation', 'value'])
df2.head(10)
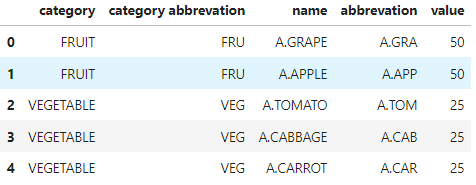
*row number under category may differ
i had check forum, nothing seems near
tried refer to this @https://stackoverflow.com/questions/62626290/how-to-merge-every-3-rows-of-a-dataframe-into-1-row-with-3-columns
but that's different, may i know how to achieve the desired format?
thanks
CodePudding user response:
IIUC the only hint you get to build categories is the value: the sum of each element in a category is equal to the category value.
You then have to keep track of the cumulated values to set your new category columns:
cat_index = 0
for index, row in df.iterrows():
if index == cat_index:
cat_value = row["value"]
cumul_value = 0
else:
cumul_value = row["value"]
df.at[index, "category"] = df.at[cat_index, "name"]
df.at[index, "category abbreviation"] = df.at[cat_index, "abbreviation"]
if cumul_value == cat_value:
cat_index = index 1
# deleting category rows:
df = df.drop(df[df["name"]==df["category"]].index).reset_index(drop=True)
print(df)
Output:
name abbreviation value category category abbreviation
0 A.GRAPE A.GRA 50 FRUIT FRU
1 A.APPLE A.APP 50 FRUIT FRU
2 A.TOMATO A.TOM 25 VEGETABLE VEG
3 A.CABBAGE A.CAB 25 VEGETABLE VEG
4 A.CARROT A.CAR 25 VEGETABLE VEG
CodePudding user response:
find the category by apply only alpha for the category. use forward fill - ffil to replace None values in category with Non-None value
data = [['FRUIT', 'FRU', 100],['A.GRAPE','A.GRA', 50],['A.APPLE','A.APP', 50],
['VEGETABLE', 'VEG', 75],['A.TOMATO','A.TOM', 25],['A.CABBAGE','A.CAB', 25],['A.CARROT','A.CAR', 25]]
df = pd.DataFrame(data, columns = ['name', 'abbrevation', 'value'])
df['Category']=df['name'].apply(lambda x: x if x.isalpha() else None)
df.ffill(inplace=True)
print(df)
output
name abbrevation value Category
0 FRUIT FRU 100 FRUIT
1 A.GRAPE A.GRA 50 FRUIT
2 A.APPLE A.APP 50 FRUIT
3 VEGETABLE VEG 75 VEGETABLE
4 A.TOMATO A.TOM 25 VEGETABLE
5 A.CABBAGE A.CAB 25 VEGETABLE
6 A.CARROT A.CAR 25 VEGETABLE