Suppose I have a dataframe with two numeric columns and one categorical column:
dftest=pd.DataFrame({
"tau":[1,2,5,1,2,5],
"x" :[4,5,6,7,8,9],
"cat":list("aaabbb")
})
Output:

I can calculate the sum of squares of x for each cat easily:
dftest.groupby(["cat"]).apply(
lambda s: pd.Series({
"sum_x^2":(s["x"]**2).sum()
})
)
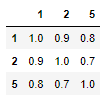
But now my question: instead of Sum_i (x_i^2) how do I calculate Sum_{i,j} rho(tau_i, tau_j) * x_i * x_j, for some square matrix rho with the correct dimensions and row/column indices? As a concrete example, suppose I have the following rho:
rho = pd.DataFrame({
1:[1, 0.9, 0.8],
2:[0.9, 1, 0.7],
5:[0.8, 0.7, 1]
}).T
rho = rho.rename(columns={0:1, 1:2, 2:5})
For category a, I would like to calculate:
rho[1,1] * x[1] * x[1] rho[1,2] * x[1] * x[2] rho[1,5] * x[1] * x[5] ...
... rho[2,1] * x[2] * x[1] ...
Or as per the example given:
1*4*4 0.9*4*5 0.8*4*6 ...
0.9*5*4 ...
Currently I'm doing this by looping through the groupby objects and looping over the index values in rho, but I'm wondering if I'm missing a more elegant way.
CodePudding user response:
First is pivoted dftest for columns by groups 1,2,5:
df = dftest.pivot('cat','tau','x')
print (df)
tau 1 2 5
cat
a 4 5 6
b 7 8 9
Then is reshaped rho for MultiIndex Series by DataFrame.stack:
s = rho.stack()
print (s)
1 1 1.0
2 0.9
5 0.8
2 1 0.9
2 1.0
5 0.7
5 1 0.8
2 0.7
5 1.0
dtype: float64
Repeated values by DataFrame.reindex in different levels:
df1 = df.reindex(s.index, level=0, axis=1)
print (df1)
1 2 5
1 2 5 1 2 5 1 2 5
cat
a 4 4 4 5 5 5 6 6 6
b 7 7 7 8 8 8 9 9 9
df2 = df.reindex(s.index, level=1, axis=1)
print (df2)
1 2 5
1 2 5 1 2 5 1 2 5
cat
a 4 5 6 4 5 6 4 5 6
b 7 8 9 7 8 9 7 8 9
Last are multiple all together with sum:
out = df1.mul(df2).mul(s).sum(axis=1)
print (out)
cat
a 193.4
b 496.4
dtype: float64