I have a big data frame (df) which contains x/y coordinates and a nonlinear regression line that is somewhere in the middle, see plot below. Many points overlap, that's why I have an extra column $Freq.
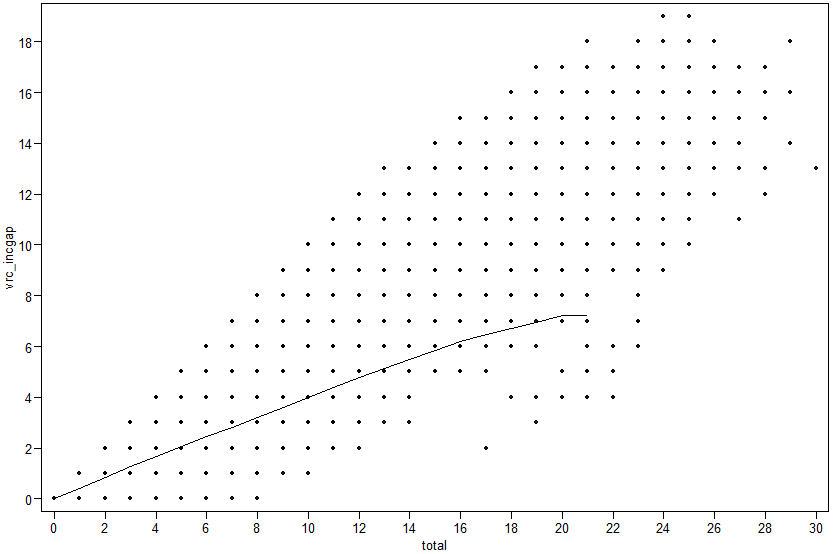
I am looking for a way to determine how many points (many on top of eachother) are above this line. See the df structure below.
head(df)
x y Freq
0 0 396
1 1 222
1 0 513
2 0 315
2 1 279
2 2 36
...
I am aware of the polygon methods here on StackOverflow but I can't seem to get those to work, maybe in part due to the fact that my line is a series of coordinates rather than a formula:
head(line)
x y
0 0.0000
1 0.4220
2 0.8350
3 1.2545
4 1.6615
5 2.0450
In the end it would be great if I can have three numbers: one that describes the count of the points above the line, the count of the points below the line, and possibly those that are to the right of this particular line.
Thanks!
CodePudding user response:
A lot of unknowns here, nevertheless
df=merge(df,line,by="x",suffixes=c("_df","_line"))
sum(df$Freq[df$y_df>df$y_line])
[1] 537
CodePudding user response:
library(tidyverse)
data <- tibble::tribble(
~x, ~y, ~Freq,
0, 0, 396,
1, 1, 222,
1, 0, 513,
2, 0, 315,
2, 1, 279,
2, 2, 36
)
data
#> # A tibble: 6 x 3
#> x y Freq
#> <dbl> <dbl> <dbl>
#> 1 0 0 396
#> 2 1 1 222
#> 3 1 0 513
#> 4 2 0 315
#> 5 2 1 279
#> 6 2 2 36
line <- tibble::tribble(
~x, ~y,
0, 0.0000,
1, 0.4220,
2, 0.8350,
3, 1.2545,
4, 1.6615,
5, 2.0450
)
line
#> # A tibble: 6 x 2
#> x y
#> <dbl> <dbl>
#> 1 0 0
#> 2 1 0.422
#> 3 2 0.835
#> 4 3 1.25
#> 5 4 1.66
#> 6 5 2.04
data %>%
left_join(line %>% rename(line_y = y)) %>%
filter(y > line_y)
#> Joining, by = "x"
#> # A tibble: 3 x 4
#> x y Freq line_y
#> <dbl> <dbl> <dbl> <dbl>
#> 1 1 1 222 0.422
#> 2 2 1 279 0.835
#> 3 2 2 36 0.835
data %>%
left_join(line %>% rename(line_y = y)) %>%
filter(y > line_y) %>%
summarise(sum(Freq))
#> Joining, by = "x"
#> # A tibble: 1 x 1
#> `sum(Freq)`
#> <dbl>
#> 1 537
data %>%
left_join(line %>% rename(line_y = y)) %>%
filter(y > line_y) %>%
nrow()
#> Joining, by = "x"
#> [1] 3
Created on 2021-11-09 by the reprex package (v2.0.1)