I have a dataframe like this, but much bigger:
Index Duration
1 100
2 300
3 350
4 200
5 500
6 1000
7 350
8 200
9 400
I want to calculate a new column with the median for every 3 rows, but in every row. Like this:
Index Duration Median
1 100
2 300 300
3 350 300
4 200 350
5 500 500
6 1000 500
7 350 350
8 200 350
9 400
So for every median row it takes 3 rows, starting at the beginning. But it always has to take one row before and one row after the own one. So that the row the median is being written, is in the middle. Because of that the first and last row has to be empty. The rest of the dataframe has to stay like it is.
Here is an example picture of it looks like in Excel:
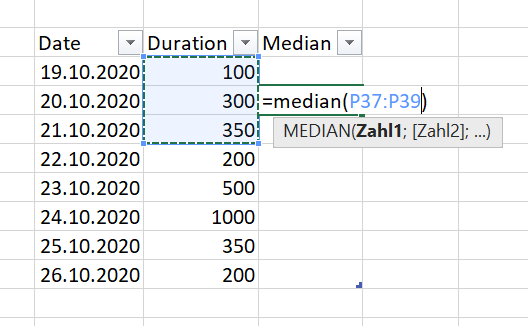
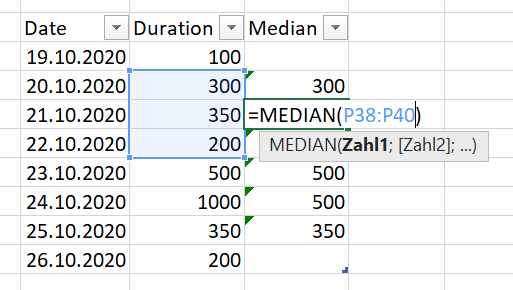
In Excel it's easy. You can just move the formula down the rows. I tried many solutions I found here, but they're not doing what I want it to be.
For example I tried this, but it just makes me 3 groups, which I don't want:
df.groupby(np.arange(len(df))//3).median()
#output:
Index Duration Median
1 100 500
2 300 350
3 350 350
I want the groups to overlap like I showed above. I hope you understood my problem and can help me with that.
CodePudding user response:
Use Series.rolling with center=True parameter:
df['Median'] = df['Duration'].rolling(3, center=True).median()
print (df)
Index Duration Median
0 1 100 NaN
1 2 300 300.0
2 3 350 300.0
3 4 200 350.0
4 5 500 500.0
5 6 1000 500.0
6 7 350 350.0
7 8 200 350.0
8 9 400 NaN
Another idea is shifting by 1 row:
df['Median'] = df['Duration'].rolling(3).median().shift(-1)
CodePudding user response:
You should consider rolling functionality of Pandas.
The syntax goes like:
DF.rolling(n-rows, center=True / False).median()
This will make you work much better.
In your case:
df.rolling(3).median()
I hope it Helps.