I have a csv file with this kind of data:
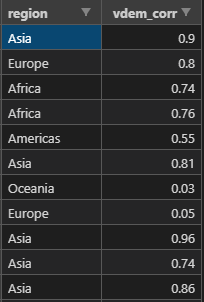
But I would like to have the columns Americas, Asia, Europe, Africa etc. with all the corresponding "vdem_corr" values under it. How can I change this in python?
CodePudding user response:
My solution is:
result = df.groupby('region').apply(lambda grp: pd.Series(
grp.vdem_corr.values)).unstack(level=1).T
The advantage over the answer by Prahken is that my result has much less NaN values.
Try on your own and compare.
CodePudding user response:
df = pd.read_csv(...)
df.pivot(columns='region', values='vdem_corr')