I want to apply function pd.cut to each column in a dataframe.
qcut is basically is Quantile-based discretization function.
Note: for parameters X
X is 1d ndarray or Series.
My dataframe:
import pandas as pd
df = pd.DataFrame({
'PC1' : [0.035182, 0.001649, -0.080456, 0.056460, 0.017737, -0.005615, 0.033691, 0.547145, -0.022938, -0.059511],
'PC2': [0.034898, 0.001629, -0.083374, 0.053976, 0.017603,-0.005902, 0.006798, 0.250167, -0.137955, -0.313852],
'PC3': [0.032212, 0.001591, -0.067145, 0.047500, 0.015782, -0.003079, 0.012376, 0.302485, -0.063795, -0.124957],
'PC4' : [-0.000632,0.001268,0.063346,-0.026841,-0.009790,0.029897,-0.018870,-0.449655,0.081417,-0.327028],
'PC5' : [0.020340,0.001734,-0.050830,0.008507,0.007470,0.013534,0.100008,1.083280,0.298315,0.736401],
'PC6' : [0.027012,0.001507,-0.036496,0.032256,0.012207,0.005451,0.081582,0.959821,0.337683,0.758737],
'PC7' : [0.027903,0.001625,-0.041970,0.039854,0.014676,0.002364,0.045583,0.620938,0.116647,0.214294],
'PC8' : [0.013828,-0.015836,-0.117484,-0.208933,-0.162090,-0.190467,-0.075784,-0.481607,-0.213148,-0.401169],
'PC9' : [0.009378,0.002712,-0.148531,0.040901,0.011923,-0.000078,-0.055367,-0.661758,0.242363,-0.392438],
'PC10' : [-0.002740,-0.000234,0.060118,0.027855,0.016309,0.009850,-0.108481,-1.560047,0.198750,-0.793165],
'PC11' : [-2.876278,-0.437754,0.764775,-0.627843,0.391284,0.090675,-0.007820,0.342359,0.052004,-0.200808],
'PC12' : [-2.411929,-0.414697,0.415683,-0.426348,0.302643,-0.160550,-0.051552,1.086344,-0.275267,1.219304]
})
df.head()
The basic way to apply pd.cut to each column in df by slicing each column. This is too long if I have lots of columns. I give an example for 5 out of 12 column in df below.
X1 = df['PC1']
X2 = df['PC2']
X3 = df['PC3']
X4 = df['PC4']
X5 = df['PC5']
PC1 = pd.qcut(X1, 2, labels=None, retbins=False, precision=3, duplicates='raise')
PC2 = pd.qcut(X2, 2, labels=None, retbins=False, precision=3, duplicates='raise')
PC3 = pd.qcut(X3, 2, labels=None, retbins=False, precision=3, duplicates='raise')
PC4 = pd.qcut(X4, 2, labels=None, retbins=False, precision=3, duplicates='raise')
PC5 = pd.qcut(X5, 2, labels=None, retbins=False, precision=3, duplicates='raise')
result: the quantile of pd.cut is stored in variable named X. As shown picture below.
X = pd.concat([PC1, PC2, PC3, PC4, PC5], axis=1)
X
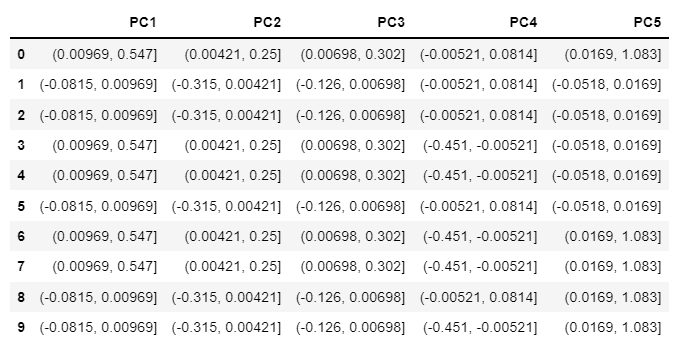
How to create a function or quick way to apply pandas.qcut to each column in a dataframe of Python with final result given above?
Next case: Then, I want to take only 2 values that are unique from each column PC1, PC2,..... PCn.
uniq = []
for i in x.columns:
uniq.append(x[i].unique())
unique = pd.DataFrame(uniq)
unique
The result look like this:

Unique variable consists 2 values in the form of (a,b]
Then I want to customize transformer class to create new categorical dummy features.
# custom transformer class to create new categorical dummy features
class WoE_Binning(BaseEstimator, TransformerMixin):
def __init__(self, X): # no *args or *kargs
self.X = X
def fit(self, X, y = None):
return self #nothing else to do
def transform(self, X):
X_new = X.loc[:, 'grade:A': 'grade:G']
X_new['PC1:0.00969 - 0.547'] = np.where((X['PC1'] > 0.00969) & (X['PC1'] <= 0.547), 1, 0)
X_new['PC1:-0.0815 - 0.00969'] = np.where((X['PC1'] > 0.0815 ) & (X['PC1'] <= 0.00969), 1, 0)
X_new['PC2:0.00421 - 0.25'] = np.where((X['PC2'] > 0.00421) & (X['PC2'] <= 0.25), 1, 0)
X_new['PC2:-0.315 - 0.00421'] = np.where((X['PC2'] > 0.315) & (X['PC2'] <= 0.00421), 1, 0)
X_new['PC3:0.00698 - 0.302'] = np.where((X['PC3'] > 7.071) & (X['PC3'] <= 10.374), 1, 0)
X_new['PC3:-0.126 - 0.00698'] = np.where((X['PC3'] > 10.374) & (X['PC3'] <= 13.676), 1, 0)
X_new['PC4:-0.00521 - 0.0814'] = np.where((X['PC4'] > 7.071) & (X['PC4'] <= 10.374), 1, 0)
X_new['PC4:-0.451 - -0.00521'] = np.where((X['PC4'] > 10.374) & (X['PC4'] <= 13.676), 1, 0)
X_new['PC5:0.0169 - 1.083'] = np.where((X['PC5'] > 7.071) & (X['PC5'] <= 10.374), 1, 0)
X_new['PC5:-0.0518 - 0.0169'] = np.where((X['PC5'] > 10.374) & (X['PC5'] <= 13.676), 1, 0)
X_new['PC6:-0.0375 - 0.0296'] = np.where((X['PC6'] > 7.071) & (X['PC6'] <= 10.374), 1, 0)
X_new['PC6:0.0296 - 0.96'] = np.where((X['PC6'] > 10.374) & (X['PC6'] <= 13.676), 1, 0)
X_new['PC7:0.0296 - 0.96'] = np.where((X['PC7'] > 7.071) & (X['PC7'] <= 10.374), 1, 0)
X_new['PC7:-0.043000000000000003 - 0.0339'] = np.where((X['PC7'] > 10.374) & (X['PC7'] <= 13.676), 1, 0)
X_new['PC8:-0.176 - 0.0138'] = np.where((X['PC8'] > 7.071) & (X['PC8'] <= 10.374), 1, 0)
X_new['PC8:-0.483 - -0.176'] = np.where((X['PC8'] > 10.374) & (X['PC8'] <= 13.676), 1, 0)
X_new['PC9:0.00132 - 0.242'] = np.where((X['PC9'] > 7.071) & (X['PC9'] <= 10.374), 1, 0)
X_new['PC9:-0.663 - 0.00132'] = np.where((X['PC9'] > 10.374) & (X['PC9'] <= 13.676), 1, 0)
X_new['PC10:-1.561 - 0.00481'] = np.where((X['PC10'] > 7.071) & (X['PC10'] <= 10.374), 1, 0)
X_new['PC10:0.00481 - 0.199'] = np.where((X['PC10'] > 10.374) & (X['PC10'] <= 13.676), 1, 0)
X_new['PC11:-2.877 - 0.0221'] = np.where((X['PC11'] > 7.071) & (X['PC11'] <= 10.374), 1, 0)
X_new['PC11:0.0221 - 0.765'] = np.where((X['PC11'] > 10.374) & (X['PC11'] <= 13.676), 1, 0)
X_new['PC12:-2.413 - -0.106'] = np.where((X['PC12'] > 7.071) & (X['PC12'] <= 10.374), 1, 0)
X_new['PC12:-0.106 - 1.219'] = np.where((X['PC12'] > 10.374) & (X['PC12'] <= 13.676), 1, 0)
X_new.drop(columns = ref_categories, inplace = True)
return X_new
Is there any faster and simple way to input (a,b] in unique variable and slice column name of X (PC1, PC2, ...PCn) into :
X_new['PC12:-0.106 - 1.219'] = np.where((X['PC12'] > a ) & (X['PC12'] <= b ), 1, 0)
on the costume class above?
CodePudding user response:
You can use a loop over the column names
cuts = []
for col in df.columns:
cuts.append(pd.qcut(df[col], 2, labels=None, retbins=False, precision=3, duplicates='raise'))
x = pd.concat(cuts, axis=1)
Instead of df.columns you can supply a list of the columns you want specifically like in your example but I assume you wanted them all