My architecture allows files to be put in s3 for which Lambda function runs concurrently. However, the files being put in S3 are somehow overwriting because of some other process in a gap of milliseconds. Those multiple put events for the same file are causing the lambda to trigger multiple times for the same event.
Is there a threshold I can set on s3 events (something that doesn't trigger the lambda multiple times for the same file event.)
Or what kind of s3 event only occurs when a file is created and not updated?
There is already a code in place which checks if the trigger file is present. if not, it creates the trigger file. But that is also of no use since the other process is very fast to put files is s3.
Something like this below -
try:
s3_client.head_object(Bucket=trigger_bucket, Key=trigger_file)
except ClientError as _:
create_trigger_file(
s3_client, trigger_bucket, trigger_file
)
CodePudding user response:
It appears your problem is that multiple invocations of the AWS Lambda function are attempting to access the same files at the same time.
To avoid this, you could modify the settings on the Lambda function to Manage Lambda reserved concurrency - AWS Lambda by setting the reserved concurrency to 1. This will only allow a single invocation of the Lambda function to run at any time.
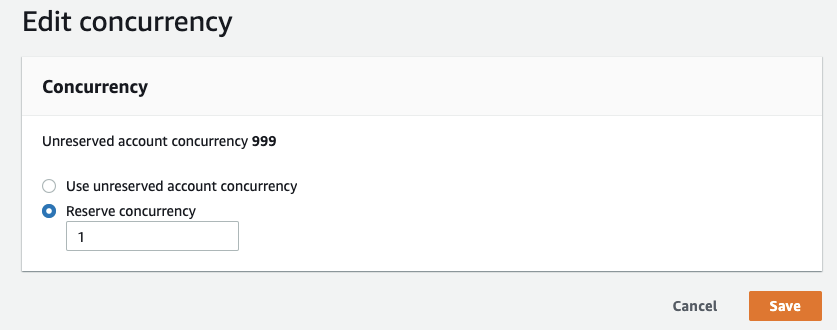
CodePudding user response:
You could configure Amazon S3 to send events to an Amazon SQS FIFO (first-in-first-out) queue. The queue could then trigger the Lambda function.
The benefit of using a FIFO queue is that each message has a Message Group ID. A FIFO queue will only provide one message to the AWS Lambda function per Message Group ID. It will not send another message with the same Message Group ID until the earlier one has been fully processed. If you set the Message Group Id to be the Key of the S3 object, then it would effectively have a separate queue for each object created in S3.
This method would allow Lambda functions to run in parallel for different objects, but for each particular Key there would only be a maximum of one Lambda function executing.
CodePudding user response:
I guess the problem is that your architecture needs to write to the same file. This is not scalable. From the documentation:
Amazon S3 does not support object locking for concurrent writers. If two PUT requests are simultaneously made to the same key, the request with the latest timestamp wins. If this is an issue, you must build an object-locking mechanism into your application.
So, think about your architecture. Why do you have a process that wants to process multiple times to the same file at the same time? The lambda's that create these S3 files, do they need to write to the same file? If I understand your use case correctly, every lambda could create an unique file. For example, based on the name of the PDF you want to create or with some timestamp added to it. That ensures you don't have write collisions. You could create lifecycle rules on the S3 bucket to delete the files after a day or so, such that you don't increase your storage costs too much. Or have a lambda delete the file when it is finished with it.