I have two datasets df1 and df2
P1 <- c('A', 'A', 'B', NA)
P2 <- c('B', NA, 'B', 'B')
P3 <- c('A', 'B', 'B', 'A')
P4 <- c('A', 'B', NA, 'B')
P5 <- c(NA, NA, NA, 'B')
df1 <- data.frame(P1, P2, P3, P4, P5, row.names = NULL)
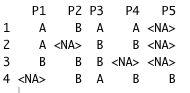
[![enter image description here][2]][2]P1 <- c('A', 'A', 'B', 'B', 'A', 'B', 'B', 'A')
P2 <- c('B', 'B', 'B', 'B', 'B', 'B', 'A', 'B')
P3 <- c('A', 'B', 'B', 'A', 'A', 'B', 'B', 'A')
P4 <- c('A', 'B', 'B', 'B', 'A', 'B', 'A', 'B')
P5 <- c('B', 'B','B', 'B', 'B', 'B', 'A', 'B')
df2 <- data.frame(P1, P2, P3, P4, P5, row.names = NULL)

I need to count how many times each row from df1 appears in df2. If a value in df1 is NA, it can be both A and B in the df2. So for example, row #4 from df1 will be counted as rows #4 and #8 in df2.
CodePudding user response:
You may try
row_appears <- c()
for (i in 1:nrow(df1)){
x <- df1[i,]
y <- df1[i,]
x[is.na(x)] <- "A"
y[is.na(y)] <- "B"
z <- sum(apply(df2, 1, function(t) all(x == t)) apply(df2, 1, function(t) all(y == t)))
row_appears <- c(row_appears, z)
}
row_appears
[1] 2 1 2 2
CodePudding user response:
Alternatively, we can treat is as a character match question, converting both data frames into character vectors, and treating NA as possibly A or B.
df1[is.na(df1)] <- "(A|B)" # regex talk for "might be A or B"
x <- do.call(paste, c(df1, sep = ""))
y <- do.call(paste, c(df2, sep = ""))
x |>
lapply(\(.) stringi::stri_count_regex(y, .)) |>
lapply(sum) |>
unlist(use.names = F)
#> [1] 2 1 2 2
CodePudding user response:
You can also use {tidyverse} or {data.table}.
library(tidyverse)
df3 <- bind_rows(
df1 |> mutate(across(everything(), replace_na, "A")),
df1 |> mutate(across(everything(), replace_na, "B"))
)
df2 |>
group_by_all() |>
summarise(N = n(), .groups = "drop") |>
right_join(df3, by = paste0("P", 1:5)) |>
mutate(N = replace_na(N, 0))
# # A tibble: 8 x 6
# P1 P2 P3 P4 P5 N
# <chr> <chr> <chr> <chr> <chr> <dbl>
# 1 A B A A B 2
# 2 A B A B B 1
# 3 A B B B B 1
# 4 B B A B B 1
# 5 B B B B B 2
# 6 A B A A A 0
# 7 A A B B A 0
# 8 B B B A A 0
library(data.table)
setDT(df1)
setDT(df2)
df1_a <- df1_b <- copy(df1)
df1_a[is.na(df1_a)] <- "A"
df1_b[is.na(df1_b)] <- "B"
df3 <- rbindlist(list(df1_a, df1_b))
df4 <-
df2[, .N, by = eval(paste0("P", 1:5))
][df3, on = paste0("P", 1:5)]
df4[, N := fifelse(is.na(N), 0, N)][]
# P1 P2 P3 P4 P5 N
# 1: A B A A A 0
# 2: A A B B A 0
# 3: B B B A A 0
# 4: A B A B B 1
# 5: A B A A B 2
# 6: A B B B B 1
# 7: B B B B B 2
# 8: B B A B B 1