I have a dataframe that I need to convert to a dictionary in a specific format. An example of the dataframe data (not real data for ease of presentation) is shown below:
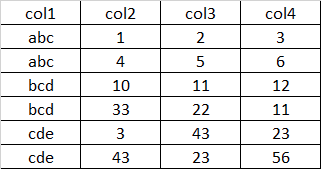
Here is csv of the input:
col1,col2,col3,col3
abc,1,2,3
abc,4,5,6
bcd,10,11,12
bcd,33,22,11
cde,3,43,23
cde,43,23,56
The resulting dictionary should be in the following format:
{ abc: [[abc, 1, 2, 3], [abc, 4, 5, 6]], bcd: [[bcd, 10, 11, 12], [bcd, 33, 22, 11]], cde: [[cde, 3, 43, 23], [cde, 43, 23, 56]] }
Is there an efficient (time to process) way to do such conversion?
CodePudding user response:
Sounds like
{k: v.to_numpy() for k, v in df.groupby(df.col1)}
does what you want; outputs
>>> {k: v.to_numpy() for k, v in df.groupby(df.col1)}
{'abc': array([['abc', 1, 2, 3], ['abc', 4, 5, 6]], dtype=object),
'bcd': array([['bcd', 10, 11, 12], ['bcd', 33, 22, 11]], dtype=object),
'cde': array([['cde', 3, 43, 23], ['cde', 43, 23, 56]], dtype=object)
}
This has the advantage of being quite fast, so long as the numpy ndarrays are suitable for further use in your case.
CodePudding user response:
You could do it like this:
from collections import defaultdict
df = pd.read_csv('test.csv')
dct = defaultdict(list)
for idx, row in df.iterrows():
values = list(row.values)
col1 = values[0]
dct[col1].append(values)
Output:
defaultdict(list,
{'abc': [['abc', 1, 2, 3], ['abc', 4, 5, 6]],
'bcd': [['bcd', 10, 11, 12], ['bcd', 33, 22, 11]],
'cde': [['cde', 3, 43, 23], ['cde', 43, 23, 56]]})