I have data as follows. Users are 1001 to 1004 (but actual data has one million users). Each user has corresponding probabilities for the variables AT1 to AT6.
user AT1 AT2 AT3 AT4 AT5 AT6
1001 0.004 0.003 0.03 0.01 0.5 0.453
1002 0.2 0.1 0.3 0.1 0.1 0.2
1003 0.07 0.13 0.22 0.3 0.08 0.2
1004 0.01 0.23 0.43 0.15 0.04 0.14
I would like to select the top 3 users for each choice based on the following data.
client choice_1 choice_2
997 AT2 AT3
223 AT6 AT5
444 AT1 AT4
121 AT1 AT5
In the output, top1 to top3 are the top 3 users based on probability for choice_1 while top4 to top6 are for choice_2. client id is not computed but given. The topN are also not computed but given as top 3 for each choice. The output should look like this:
client top1 top2 top3 top4 top5 top6
997 1004 1003 1002 1004 1002 1003
223 1001 1002 1003 1001 1002 1003
444 1002 1003 1004 1004 1003 1002
121 1002 1003 1004 1001 1002 1003
How can I construct the last dataframe in python?
CodePudding user response:
I have no idea how this will scale to a million rows, but have a go with this dictionary comprehension:
# Set up test df's and re-index.
df_user = pd.DataFrame({
"user":[1001,1002,1003,1004],
"AT2" :[0.003, 0.1, 0.13, 0.23],
"AT3" :[0.03, 0.3, 0.22, 0.43],
"AT5" :[0.5, 0.1, 0.08, 0.04],
"AT6" :[0.453,0.2,0.2,0.14]
})
df_user.set_index("user", inplace=True)
df_client = pd.DataFrame({
"client":[997, 223],
"choice_1":["AT2","AT6"],
"choice_2":["AT3", "AT5"]
})
# dictionary comprehension
pd.DataFrame({row["client"]:np.append(df_user[row["choice_1"]].nlargest(3).index.values,
df_user[row["choice_2"]].nlargest(3).index.values)
for (i, row) in df_client.iterrows()}).T
Output (you still have to rename the columns, obviously):
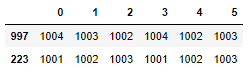
Short explanation: run the following code to see that the iterables in df.iterrows() are tuples of (a) the index of the dataframe (b) the columns.
for it in df_client.iterrows():
print(it)
Once you've run that last snippet, it will contain the last row of df_client, so set row = it[1] to experiment with the various bits of information that you can extract from this. In particular, row["choice_1"] gives you something like "AT1", from which you can extract the corresponding column from df_user, upon which you can use the pandas nlargest function. The dictionary comprehension follows trivially once you've put together all the bits.