Now I have a data frame with entries like '7M'as a string where M is Million and I want to change it to 7000000 This is a look from the data frame
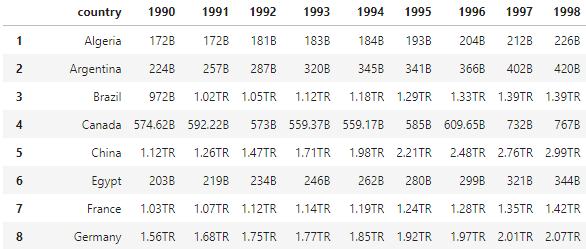
I have tried to make a function to separate the numbers from the letter and changing the letter to a number and it worked
def num_repair(x):
if 'B' in x:
l = 10**9
x = x[:-1]
x = pd.to_numeric(x)
x = x * l
elif 'TR' in x:
l = 10**12
x =x[:-2]
x = pd.to_numeric(x)
x = x * l
elif 'M' in x:
l = 10**6
x = x[:-1]
x = pd.to_numeric(x)
x = x * l
return(x)
and when I tried to apply it to the data frame it didn't give me anything any help please?
CodePudding user response:
TL;DR:
What you are looking for is .applymap()
Details:
Your method is actually written well and can be used in .apply() as-is, for a pandas.Series object, but I assume that if you are experiencing issues, it is due to the fact that you are probably using it for a pandas.DataFrame, against multiple columns.
In such a case, the argument passed to num_repair is actually of type pandas.Series, which num_repair is not really meant to support.
I can only assume, since the code that uses num_repair isn't given. Consider adding it for the completeness of the question.
If so, you can use it as follows:
df = pd.DataFrame([
['1M', '1B', '1TR'],
['22M', '22B', '22TR'],
], columns=[1990, 1991, 1992])
df.applymap(num_repair)
output:
1990 1991 1992
0 1000000 1000000000 1000000000000
1 22000000 22000000000 22000000000000
Side Note
If you want to apply it to all columns except the country, since the name may contain B / TR / M - you can do the following:
df = pd.DataFrame([
['countryM', '1M', '1B', '1TR'],
['countryB', '22M', '22B', '22TR'],
], columns=['country', 1990, 1991, 1992])
df.loc[:, df.columns.drop('country')] = df.loc[:, df.columns.drop('country')].applymap(num_repair)
df
output:
country 1990 1991 1992
0 countryM 1000000 1000000000 1000000000000
1 countryB 22000000 22000000000 22000000000000
CodePudding user response:
Works fine on my toy example:
>>> df = pd.DataFrame({'a': ['32M', '13B', '33TR']})
>>> df['a'].apply(num_repair)
0 32000000
1 13000000000
2 33000000000000