I have a dataset with column of type StringType(). The values in these money columns contains abbreviations like K and M.
I would like to remove 'K' and 'M' and multiple them either by 1000 or 1000000 for K/M respectively. I tried creating a function and use it to add a new column in the dataframe. I keep getting the following error
ValueError: Cannot convert column into bool: please use '&' for 'and', '|' for 'or', '~' for 'not' when building DataFrame boolean expressions.
The Column values are as follows:
def convertall(ReleaseClause):
if ReleaseClause == None:
return 0
elif expr("substring(ReleaseClause,-1,length(ReleaseClause))")=='K':
remove_euro=expr("substring(ReleaseClause,2,length(ReleaseClause))")
remove_K=translate(remove_euro,'K','')
remove_Kint=remove_K.cast(IntegerType())*lit(1000)
return remove_Kint
elif expr("substring(ReleaseClause,-1,length(ReleaseClause))")=='M':
remove_euro=expr("substring(ReleaseClause,2,length(ReleaseClause))")
remove_M=translate(remove_euro,'M','')
remove_Mint=remove_M.cast(IntegerType())*lit(1000000)
return remove_Mint
else:
return ReleaseClause
CodePudding user response:
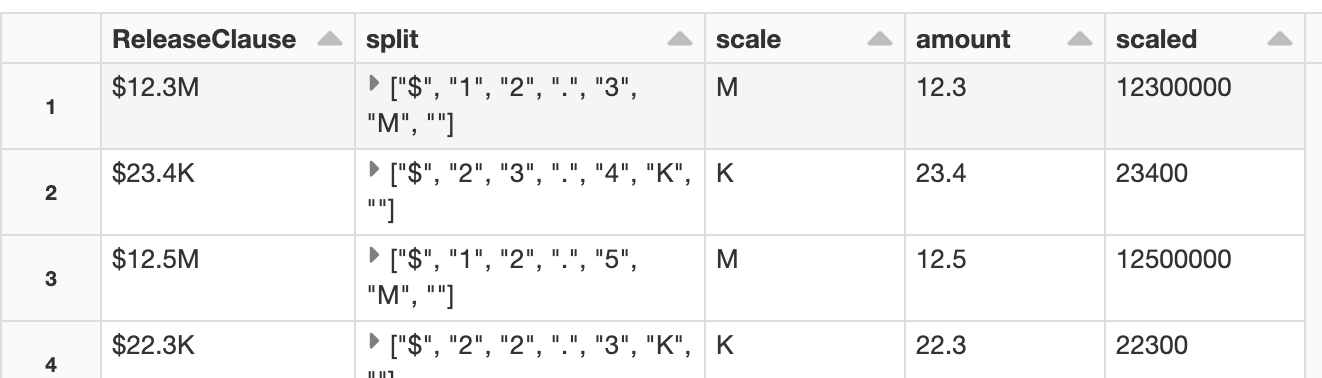
The following code converts the data using F.when() function. Before that, the string is split into letters, then M/K symbol is extracted, as well as the amount to be multiplied. This solution assumes the string size remains the same and the position of M/K symbol as well as the amount data is not variable across rows.
import pyspark.sql.functions as F
data = [("$12.3M",),
("$23.4K",),
("$12.5M",),
("$22.3K",)]
df = spark.createDataFrame(data, schema=["ReleaseClause"])
df_ans = (df
.select("ReleaseClause",
(F.split("ReleaseClause",'').alias("split")))
.withColumn("scale", F.col("split")[5])
.withColumn("amount",
F.concat(F.col("split")[1], F.col("split")[2],
F.col("split")[3], F.col("split")[4])
.cast("double"))
.withColumn("scaled", F.when(F.col("scale")=="K",
F.col("amount")*1000)
.when(F.col("scale")=="M",
F.col("amount")*1000000))
This produces output as
CodePudding user response:
You could check if value contains K or M, extract the number and multiply.
Example:
data = [("$12.3M",), ("$23.4K",), ("$12.5M",), ("$22.3K",)]
df = spark.createDataFrame(data, schema=["ReleaseClause"])
df = df.withColumn(
"result",
F.when(
F.col("ReleaseClause").contains("K"),
F.regexp_extract(F.col("ReleaseClause"), "(\d (.\d )?)", 1).cast(DoubleType())
* 1000,
)
.when(
F.col("ReleaseClause").contains("M"),
F.regexp_extract(F.col("ReleaseClause"), "(\d (.\d )?)", 1).cast(DoubleType())
* 1000000,
)
.cast(IntegerType()),
)
Result:
------------- --------
|ReleaseClause|result |
------------- --------
|$12.3M |12300000|
|$23.4K |23400 |
|$12.5M |12500000|
|$22.3K |22300 |
------------- --------