I wanted to re-label the healthy label (0) to failure label (1) 3 days before the actual failure (1) like what they did in the attached link: 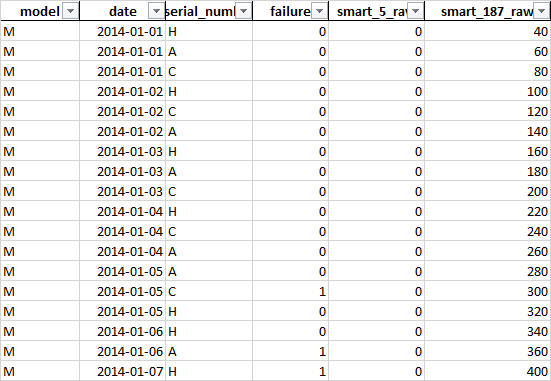
CodePudding user response:
Here is a working solution. Note: I preferred to rewrite it completely for clarity.
import pandas as pd
import numpy as np
import datetime
from datetime import date, timedelta
df = pd.read_excel('content/failure.xlsx')
df['date'] = pd.to_datetime(df['date'])
df = df.sort_values(by="date").reindex_like(df) # We need to rebuild the index adter sorting
d = datetime.timedelta(days = 3)
failed=df[df['failure']==1] # disks that actually failed
for hdd in failed['serial_number']: # for each hdd
ind=df.index[df['serial_number']==hdd] # look for that patricular hdd in df
# Note: the last element of ind corresponds to the failure date for hdd
failure_date=df.iloc[ind[-1],1] # [rows,column==1] --> (:,'date')
for i in ind[:-1]:
if (failure_date - df.iloc[i,1]).days <= d.days:
df.iloc[i,3]=1 # set failure to 1
print('hdd: A')
print(df[df['serial_number']=='A'])
print('hdd: C')
print(df[df['serial_number']=='C'])
print('hdd: H')
print(df[df['serial_number']=='H'])
Resulting in:
hdd: A
model date serial_number failure smart5 smart187
1 M 2014-01-01 A 0 0 60
5 M 2014-01-02 A 0 0 140
7 M 2014-01-03 A 1 0 180
11 M 2014-01-04 A 1 0 260
12 M 2014-01-05 A 1 0 280
16 M 2014-01-06 A 1 0 360
hdd: C
model date serial_number failure smart5 smart187
2 M 2014-01-01 C 0 0 80
4 M 2014-01-02 C 1 0 120
8 M 2014-01-03 C 1 0 200
10 M 2014-01-04 C 1 0 240
13 M 2014-01-05 C 1 0 300
hdd: H
model date serial_number failure smart5 smart187
0 M 2014-01-01 H 0 0 40
3 M 2014-01-02 H 0 0 100
6 M 2014-01-03 H 0 0 160
9 M 2014-01-04 H 1 0 220
14 M 2014-01-05 H 1 0 320
15 M 2014-01-06 H 1 0 340
17 M 2014-01-07 H 1 0 400