My question is a little unclear, but that's because I really don't know how to ask it more clearly at this stage ..
If I get an answer I will rename it more accurately.
I am a complete newbie to scraping and just learning how to do it.
I am trying to scrape just one value from 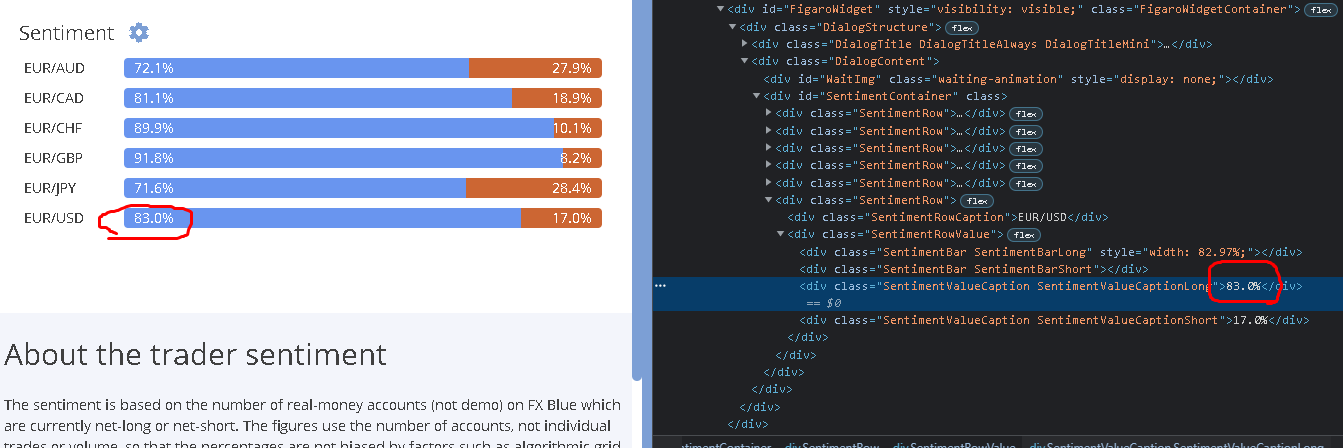
library("rvest")
url <- "https://www.fxblue.com/market-data/tools/sentiment"
web <- read_html(url)
nodes <- html_nodes(web,".SentimentValueCaptionLong")
get
html_text(nodes)
character(0)
my next try
library(RSelenium)
rD <- rsDriver(browser="chrome",port=0999L,verbose = F,chromever = "95.0.4638.54")
remDr <- rD[["client"]]
remDr$maxWindowSize()
remDr$navigate("https://www.fxblue.com/market-data/tools/sentiment")
html <- remDr$getPageSource()[[1]]
page <- read_html(html)
nodes <- html_nodes(page, ".SentimentValueCaptionLong")
get the same
html_text(nodes)
character(0)
Can someone show me how to do it right, and explain what you did
CodePudding user response:
library(rvest)
library(dplyr)
library(RSelenium)
driver = rsDriver(browser = c("firefox"))
remDr <- driver[["client"]]
remDr$navigate(url)
Get name
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes('.SentimentRowCaption') %>%
html_text()
[1] "AUD/CAD" "AUD/JPY" "AUD/NZD" "AUD/USD" "CAD/JPY" "DAX" "EUR/AUD" "EUR/CAD" "EUR/CHF" "EUR/GBP" "EUR/JPY" "EUR/USD" "GBP/AUD" "GBP/CAD" "GBP/CHF"
[16] "GBP/JPY" "GBP/USD" "NZD/USD" "USD/CAD" "USD/CHF" "USD/JPY" "XAU/USD"
Get long figures
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes('.SentimentValueCaptionLong') %>%
html_text()
[1] "79.2%" "38.4%" "56.1%" "68.9%" "26.8%" "28.7%" "68.7%" "79.5%" "80.7%" "85.3%" "57.0%" "76.4%" "36.1%" "67.4%" "69.7%" "54.9%" "82.3%" "65.1%" "25.0%"
[20] "28.7%" "17.9%" "82.8%"
Get short figures
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes('.SentimentValueCaptionShort') %>%
html_text()
[1] "20.8%" "61.4%" "43.5%" "31.3%" "73.8%" "70.8%" "31.7%" "20.0%" "19.9%" "14.3%" "43.5%" "23.4%" "64.0%" "32.2%" "30.0%" "45.8%" "17.7%" "34.8%" "74.5%"
[20] "71.3%" "82.2%" "17.0%"