Background: I have a table like the below where I'm trying to get the median value based on a rolling 30 day lookback from each created_date partitioned by each city.
The problem is that I have missing dates for some cities so bound by rows preceding won't work in this situation.
Note: I do have a date-spine table that I can leverage, but not sure if it's helpful here
| CREATED_DATE | CITY | VALUE |
|---|---|---|
| 2018-08-30 | Charlotte | 374900 |
| 2018-08-31 | Charlotte | 272000 |
| 2018-09-10 | Charlotte | 1 |
| 2018-09-24 | Charlotte | 365000 |
| 2018-10-04 | Charlotte | 342000 |
| 2018-10-07 | Charlotte | 460000 |
| 2018-10-08 | Charlotte | 91000 |
| 2018-10-15 | Charlotte | 342000 |
| 2018-10-18 | Charlotte | 155000 |
| 2018-10-19 | Charlotte | 222000 |
| ... | ... | ... |
Expected Output:
| CREATED_DATE | CITY | VALUE | MOVING_MEDIAN_30_DAY |
|---|---|---|---|
| 2018-08-30 | Charlotte | 374900 | 374900 |
| 2018-08-31 | Charlotte | 272000 | 323450 |
| 2018-09-10 | Charlotte | 1 | 272000 |
| 2018-09-24 | Charlotte | 365000 | 318500 |
| 2018-10-04 | Charlotte | 342000 | 342000 |
| 2018-10-07 | Charlotte | 460000 | 353500 |
| 2018-10-08 | Charlotte | 91000 | 342000 |
| 2018-10-15 | Charlotte | 342000 | 342000 |
| 2018-10-18 | Charlotte | 155000 | 342000 |
| 2018-10-19 | Charlotte | 222000 | 342000 |
| ... | ... | ... | ... |
Question: How can I get to my expected output using sql / snowflake?
Thanks in advance!!
CodePudding user response:
Since Snowflake's MEDIAN window function doesn't support sliding frames, we must take another approach. We can use Snowflake's MEDIAN aggregate function, along with a self-join, to simulate a window function.
SELECT original.created_date
, original.city
, original.value
, MEDIAN(window.value) AS rolling_30_day_median
FROM cities AS original
LEFT JOIN cities AS window
ON original.city = window.city
AND DATEDIFF(days, original.created_date, window.created_date) BETWEEN -30 AND 0
GROUP BY 1, 2, 3
ORDER BY 1
;
This produces the desired output.
| CREATED_DATE | CITY | VALUE | ROLLING_30_DAY_MEDIAN |
|---|---|---|---|
| 2018-08-30 | Charlotte | 374,900 | 374,900 |
| 2018-08-31 | Charlotte | 272,000 | 323,450 |
| 2018-09-10 | Charlotte | 1 | 272,000 |
| 2018-09-24 | Charlotte | 365,000 | 318,500 |
| 2018-10-04 | Charlotte | 342,000 | 342,000 |
| 2018-10-07 | Charlotte | 460,000 | 353,500 |
| 2018-10-08 | Charlotte | 91,000 | 342,000 |
| 2018-10-15 | Charlotte | 342,000 | 342,000 |
| 2018-10-18 | Charlotte | 155,000 | 342,000 |
| 2018-10-19 | Charlotte | 222,000 | 342,000 |
CodePudding user response:
I tried using the MEDIAN but looks like it is not getting the value you want, what you may want to do is use LAG function and create a moving average variable. THis is non the assumption of that you have data for all the days and the 1st 29 days you may get 0 value.
select CREATED_DATE,CITY, VALUE, --month(CREATED_DATE),
median (value) over (Partition by city, month(CREATED_DATE)) as med,
(value lag(value,1) over (Partition by city order by CREATED_DATE)
lag(value,2) over (Partition by city order by CREATED_DATE)
lag(value,3)over (Partition by city order by CREATED_DATE)
--....
lag(value,30) over (Partition by city order by CREATED_DATE) ) / 30 as movingaverage
--over (order by CREATED_DATE)
from test_dt;
create or replace table test_dt as
(select to_date('2018-08-30') as CREATED_DATE, 'Charlotte' as CITY, 374900 as VALUE UNION ALL
select'2018-08-31','Charlotte', 272000 from dual UNION ALL
select'2018-09-10','Charlotte', 1 from dual UNION ALL
select'2018-09-24','Charlotte', 365000 from dual UNION ALL
select'2018-10-04','Charlotte', 342000 from dual UNION ALL
select'2018-10-07','460000',0 from dual UNION ALL
select'2018-10-08','Charlotte', 91000 from dual UNION ALL
select'2018-10-15','Charlotte', 342000 from dual UNION ALL
select'2018-10-18','Charlotte', 155000 from dual UNION ALL
select'2018-10-19','Charlotte', 222000
);
select CREATED_DATE,CITY, VALUE, --month(CREATED_DATE),
median (value) over (Partition by city, month(CREATED_DATE)) as med from test_dt;
CodePudding user response:
This is a great problem to solve with a UDTF:
with data as (
select $1 n, '2021-01-01'::date 7*seq8() d, 'Rivendell' city
from values(1),(2),(3),(33),(10),(-5),(13),(20),(40),(80),(1),(4),(-5)
)
select a.*, median
from data a
, table(running_median_30_days(n::float, d) over(partition by city order by d));
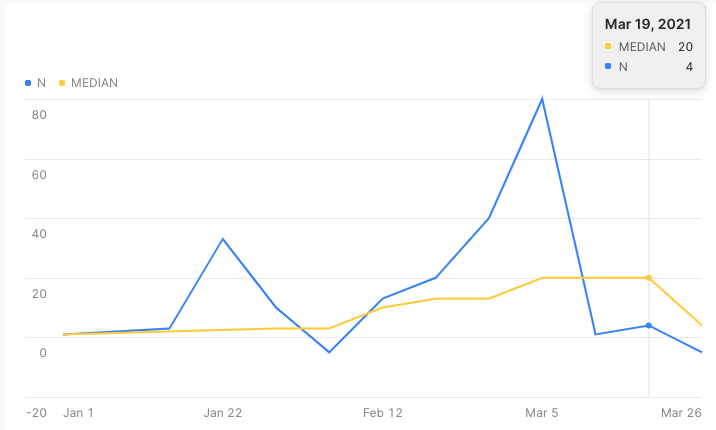
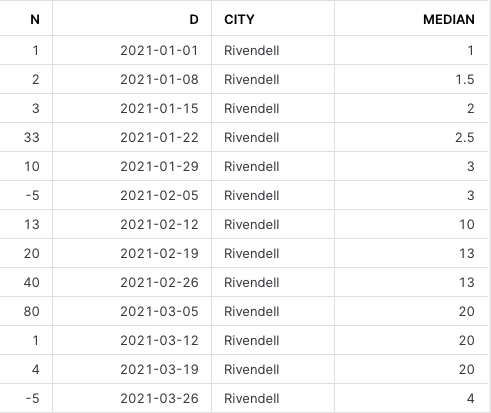
The definition of the UDTF is more complicated that the self-join solution by TJ, but it helps encapsulate the desired behavior behind a named function:
create or replace function running_median_30_days(N float, D date)
returns table(MEDIAN float)
language javascript
as $$
{
processRow: function f(row, rowWriter, context){
// Store history.
this.pointarr.push({n:row.N, d:row.D});
// Discard >30 days.
this.pointarr = this.pointarr.filter(x=> this.dateDiffInDays(x.d, row.D)<30);
// Return median.
rowWriter.writeRow({MEDIAN: this.median(this.pointarr.map(x=> x.n))});
}
, initialize: function(argumentInfo, context) {
this.pointarr = [];
this.median = function(values){
// https://stackoverflow.com/a/45309555/132438
values.sort(function(a,b){
return a-b;
});
var half = Math.floor(values.length / 2);
if (values.length % 2) return values[half];
return (values[half - 1] values[half]) / 2.0;
}
this.dateDiffInDays = function (a, b) {
// https://stackoverflow.com/a/15289883/132438
var utc1 = Date.UTC(a.getFullYear(), a.getMonth(), a.getDate());
var utc2 = Date.UTC(b.getFullYear(), b.getMonth(), b.getDate());
return Math.floor((utc2 - utc1) / (1000 * 60 * 60 * 24));
}
}
}
$$;
What complicated the solution further:
- Sorting numbers and calculating medians in JS is not straightforward, so we had to define functions to do so.
- Finding days between dates in JS is not straightforward, so we had to define a function for that too.
As advantages:
- A UDTF should scale better than a self join, since it processes each row only once.
- The logic for storing only 30 days of history and calculating the median lives within it.
Read more: