I tried to extract tables from PDFs that are not in proper format that I think. The tables in these PDFs have a table format but not enclosed properly with verical borders.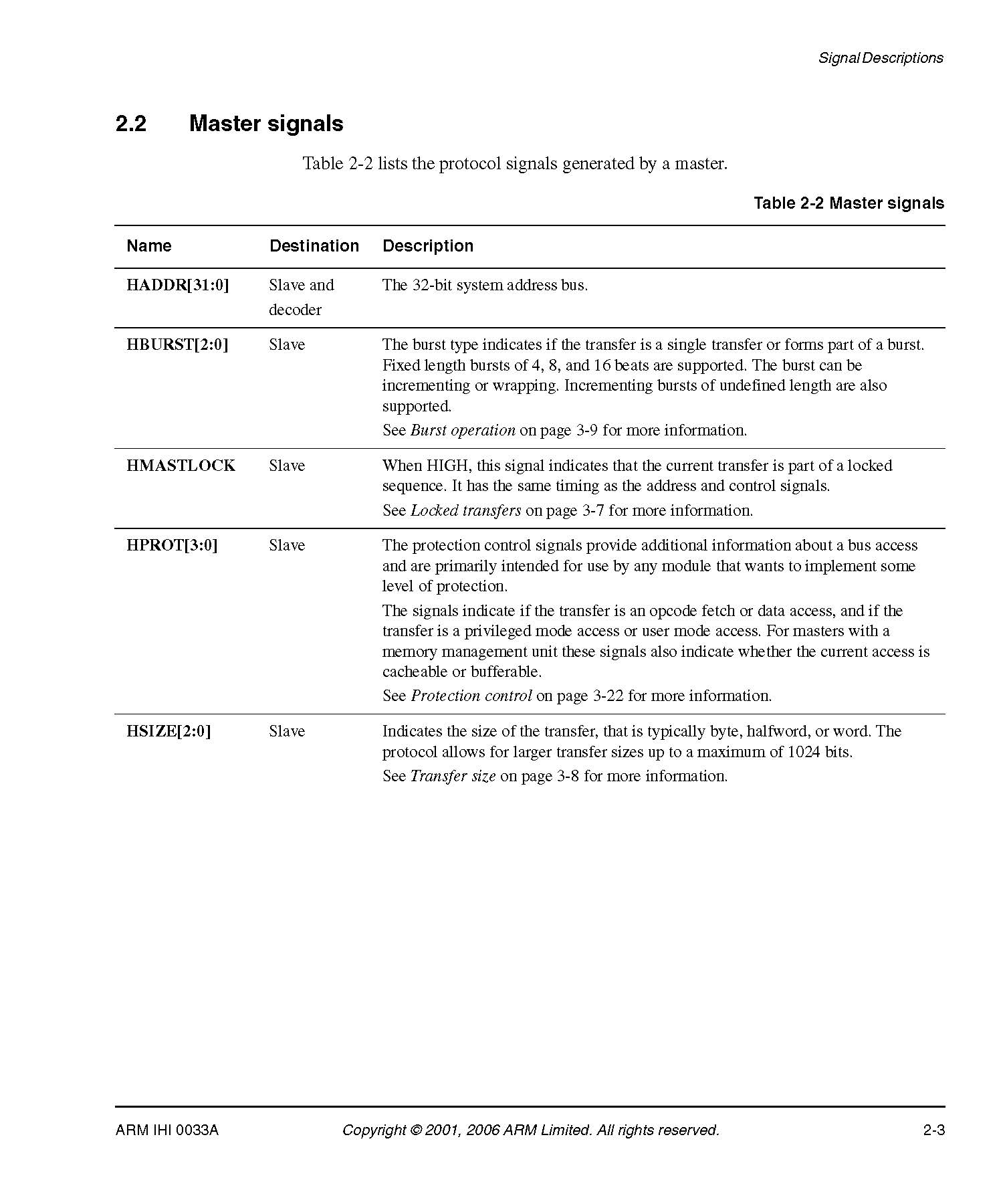 I'll attach the sample pdf and output with both libraries. When I tried to use tabula for table detection, a blank datadrame is returned on all the pages in pdf.
I'll attach the sample pdf and output with both libraries. When I tried to use tabula for table detection, a blank datadrame is returned on all the pages in pdf.
enter 0 for single pages, 1 for all, 2 for specific page: 2 enter page number: 25 no tables found on this page by tabula.
And when I use camelot there is same no response when i use flovor='lattice'
enter 0 for single pages, 1 for all pages, 2 for pages in tables are detected by tabula, 3 for specific pages: 3 enter 0 for lattice or 1 for stream: 0 enter page number: 25 no tables found on this page by camelot.
and when I use flovor='stream', I get a dataframe that has each line read line by line with tab separated data, but it will include normal text as well in that dataframe.
enter 0 for single pages, 1 for all pages, 2 for pages in tables are detected by tabula, 3 for specific pages: 3 enter 0 for lattice or 1 for stream: 1 enter page number: 25
I just need an efficient way to detect table and extract the same data if vertical enclosing table lines are not present. Both tabula and camelot libraries are working fine if table is in proper format enclosed by vertical and horizontal lines.
CodePudding user response:
This method might help you: https://camelot-py.readthedocs.io/en/master/user/advanced.html#specify-column-separators
You can find specifiy the vertical seperator to camelot by passing x coordinates, first you should use the ".plot()" method in camelot to see the table inside the pdf and make note of the x coordinates where you want the vertical seperators to be then pass them in like below:
# to get the x-coordinates
tables = camelot.read_pdf('your_pdf.pdf')
camelot.plot(tables[0], kind='text').show()
#to pass the x-coordinates
camelot.read_pdf('your_pdf.pdf', flavor='stream', columns=['x1,x2'])
CodePudding user response:
Tables not detected with tabula and camelot
I have been recently working to extract table from PDF.
Tabula and camelot didnt work for me either but pdfplumber got me required result.
import pdfplumber
pdf = pdfplumber.open(filepath)
table = pdf.pages[1].extract_table(table_settings=
{"vertical_strategy": "text", "horizontal_strategy": "text"})
df = pd.DataFrame(table, columns=table)
df.to_csv(outfile2, mode='a', index=False)