I understand that in the leaf node of clustered index the table record is stored together with say primary key.
But I found some articles stated that primary key is stored with block address of real record instead of real table record.
Could you tell me which is correct?
(1)store block address
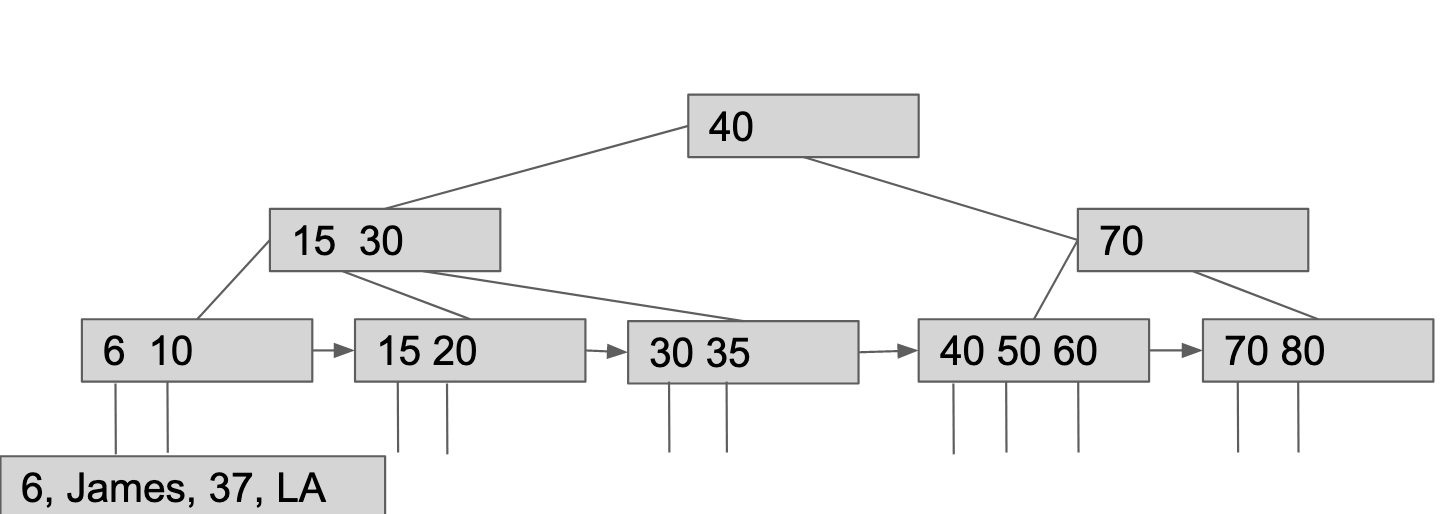
(2)store real data
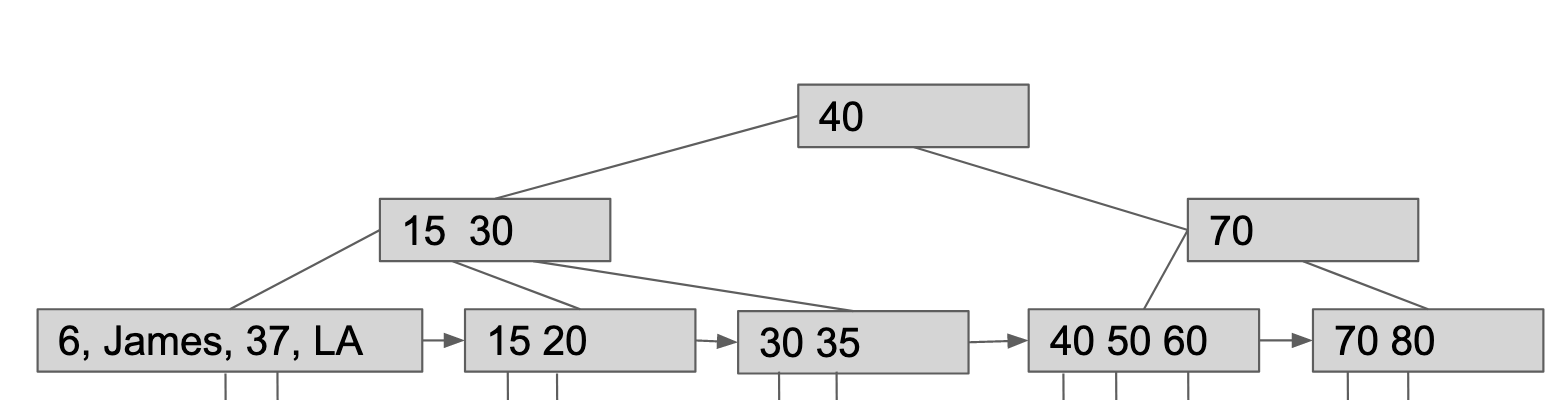
CodePudding user response:
Be careful what you read. Be sure the article talks about "MySQL" and its main 'engine' "InnoDB".
primary key is stored with block address of real record instead of real table record.
Several entire rows are stored in each leaf node (block) of the data's B Tree. That BTree is ordered by the PRIMARY KEY, which is (obviously) part of the row.
The only "block addresses" are the links you have in both of your diagrams.
I vote for your number 2 diagram, with these provisos:
- There is a 4-column row with id=6 and other columns of James, 37, LA.
- The row with id=15 is not fully shown. That is, you left out the other 3 columns.
A "block" is 16KB and can hold between 1 and several hundred rows, depending on
- size of rows,
- whether rows have been deleted, leaving 'free' space,
- etc.
(100 rows per block for either data or index is a simple Rule of Thumb.)
CodePudding user response:
In the context of mysql and innodb, from the mysql official page https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
Each InnoDB table has a special index called the clustered index that stores row data.
If a table is large, the clustered index architecture often saves a disk I/O operation when compared to storage organizations that store row data using a different page from the index record.
Based on above facts, especially number 2, I believe #2 is the correct one. From my side the reasons are (1)save one time I/O. If leaf node save the page address, there will be one more time of I/O to fetch the record.
(2)more maintainability. If page split happened and the leaf node save the page address only, there will be a lot of trouble for clustered index to update the record data page address.
However, the reason why I think #1 has points is that saving address only is cheaper than saving whole row of record data and thus store more index.