Lets assume that there is the following BigQuery database:
| asset_id | latitude | longitude | trip_status | timestamp |
|---|---|---|---|---|
| 2 | 52.1052016 | 10.141829999999999 | false | 1638274080 |
| 2 | 52.10512 | 10.1420266 | false | 1638274081 |
| 2 | 52.104774899999995 | 10.1427066 | true | 1638274085 |
| 2 | 52.1044833 | 10.1431966 | true | 1638274088 |
| 2 | 52.104156599999996 | 10.143821599999999 | true | 1638274092 |
| 2 | 52.10398 | 10.1441433 | true | 1638274094 |
| 2 | 52.1038016 | 10.1444783 | true | 1638274096 |
| 2 | 52.1036183 | 10.144823299999999 | true | 1638274098 |
| 2 | 52.1034333 | 10.1451783 | true | 1638274100 |
| 2 | 52.1032483 | 10.1455383 | false | 1638274102 |
| 2 | 52.1030533 | 10.145886599999999 | true | 1638274104 |
| 2 | 52.1028666 | 10.146175 | true | 1638274106 |
| 2 | 52.10279 | 10.1463266 | true | 1638274108 |
| 2 | 52.1026616 | 10.1466566 | true | 1638274110 |
| 2 | 52.102464999999995 | 10.147016599999999 | true | 1638274112 |
| 2 | 52.102215 | 10.1474083 | true | 1638274114 |
| 2 | 52.101968299999996 | 10.147795 | true | 1638274116 |
| 2 | 52.101756599999995 | 10.148195 | false | 1638274117 |
| 2 | 52.101538299999994 | 10.14864 | false | 1638274119 |
| 2 | 52.1013583 | 10.149076599999999 | false | 1638274121 |
In provided data there is a flag - trip_status, indicating, whether the given coordinates have been captured during the trip mode.
trip_statusvalue changing fromfalsetotrueindicates the start of the trip.trip_statusvalue changing fromtruetofalseindicates the end of the trip.- All consecutive rows with
trip_status = trueare rows belonging to the same trip
Question:
Is there a way in BigQuery to extract separate trips from such dataset? Maybe somehow group data where trip_status flag is true and return as a separate datasets?
For example, from given data, I need to retrieve something like:
Trip 1:
| asset_id | latitude | longitude | trip_status | timestamp |
|---|---|---|---|---|
| 2 | 52.104774899999995 | 10.1427066 | true | 1638274085 |
| 2 | 52.1044833 | 10.1431966 | true | 1638274088 |
| 2 | 52.104156599999996 | 10.143821599999999 | true | 1638274092 |
| 2 | 52.10398 | 10.1441433 | true | 1638274094 |
| 2 | 52.1038016 | 10.1444783 | true | 1638274096 |
| 2 | 52.1036183 | 10.144823299999999 | true | 1638274098 |
| 2 | 52.1034333 | 10.1451783 | true | 1638274100 |
Trip 2:
| asset_id | latitude | longitude | trip_status | timestamp |
|---|---|---|---|---|
| 2 | 52.1030533 | 10.145886599999999 | true | 1638274104 |
| 2 | 52.1028666 | 10.146175 | true | 1638274106 |
| 2 | 52.10279 | 10.1463266 | true | 1638274108 |
| 2 | 52.1026616 | 10.1466566 | true | 1638274110 |
| 2 | 52.102464999999995 | 10.147016599999999 | true | 1638274112 |
| 2 | 52.102215 | 10.1474083 | true | 1638274114 |
| 2 | 52.101968299999996 | 10.147795 | true | 1638274116 |
Or, even better, something like:
| row | asset_id | origin.latitude | origin.longitude | destination.latitude | destination.longitude | polyline | start_timestamp | end_timestamp |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 52.104774899999995 | 10.1427066 | 52.1034333 | 10.1451783 | ST_MAKELINE from all trip coordinates | 1638274085 | 1638274100 |
| 1 | 2 | 52.1030533 | 10.145886599999999 | 52.101968299999996 | 10.147795 | ST_MAKELINE from all trip coordinates | 1638274104 | 1638274116 |
CodePudding user response:
Consider below approach
select id, trip_number,
array_agg(struct(latitude as origin_latitude, longitude as origin_longitude) order by timestamp limit 1)[offset(0)].*,
array_agg(struct(latitude as destination_latitude, longitude as destination_longitude) order by timestamp desc limit 1)[offset(0)].*,
st_makeline(array_agg(st_geogpoint(longitude, latitude) order by timestamp)) as polyline,
min(timestamp) as start_timestamp,
max(timestamp) as end_timestamp,
from (
select * except(trip_status, prev_status, next_status),
countif(trip_start_end = 'trip_start') over win trip_number
from (
select *,
case
when trip_status and not prev_status then 'trip_start'
when trip_status and not next_status then 'trip_end'
else ''
end trip_start_end
from (
select *,
ifnull(lag(trip_status) over win, false) prev_status,
ifnull(lead(trip_status) over win, false) next_status
from your_table
window win as (partition by id order by timestamp)
)
)
where trip_status
window win as (partition by id order by timestamp)
)
group by id, trip_number
if applied to sample data in y our question - output is

and in geo visualization it shows
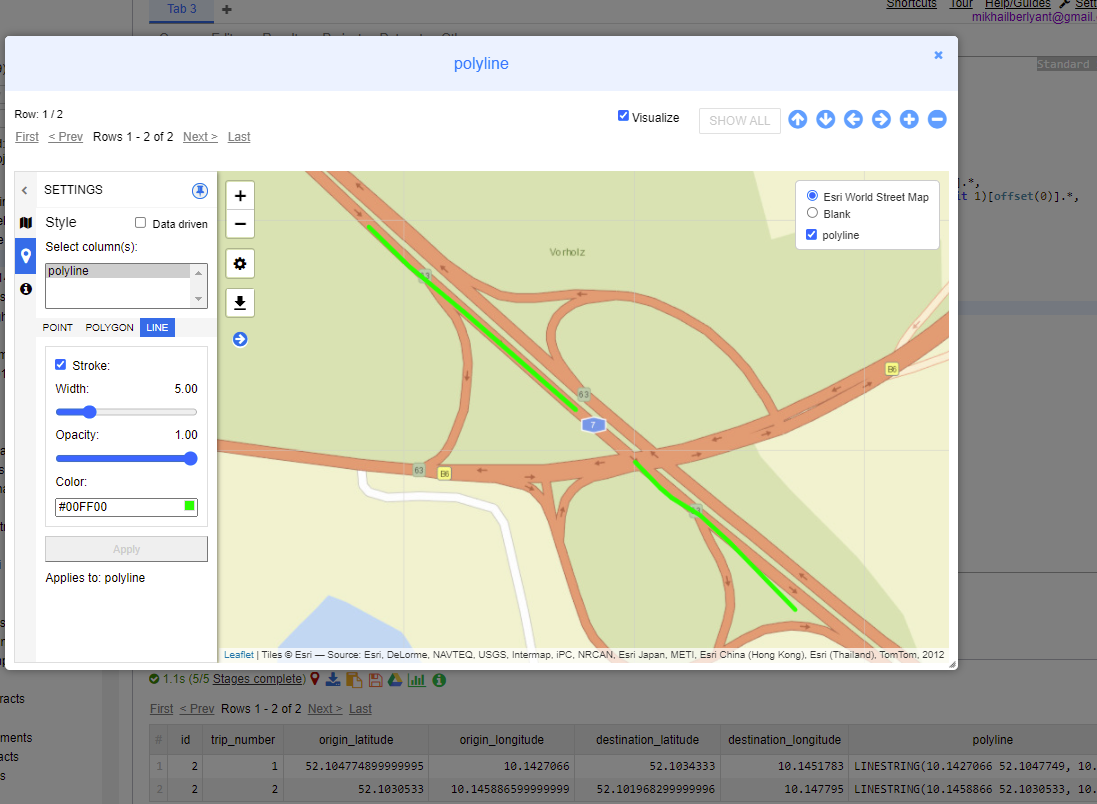
CodePudding user response:
An important point to consider is that you have to order your data explicitly based on timestamps. Becuase if you simply select your data from a table in BQ, it will give you random rows. So, in case (such as yours), always do order by timestamp.
Here is an approach to solving this problem. First, figure out the previous trip_status against each row from your ordered dataset (lag). Then use the previous trip and current trip status (based on your logic) to determine trip start and end points. Then use these rows to group the values falling in between.
with formatted as (
select
asset_id,
lat,
lon,
ts,
trip_status,
first_value(flag) over (partition BY grp order by ts) as trip_id,
st_geogpoint(lat, lon) as geo_point
from (
select
asset_id,
lat,
lon,
ts,
trip_status,
flag,
sum(case when flag is null then 0 else 1 end) over (order by ts) as grp
from (
select
asset_id,
lat,
lon,
trip_status,
case
when previous_trip_status = false and current_trip_status = true then concat('START', '->', cast(ts AS string))
when previous_trip_status = true and current_trip_status = false then concat('END', '->', cast(ts AS string))
end as flag,
ts
from (
select
asset_id,
lat,
lon,
trip_status,
timestamp,
lag(trip_status) over (order by 1=1) as previous_trip_status,
trip_status as current_trip_status,
timestamp AS ts
from `mydataset.mytable`
)
)
)
where trip_status = true
)
select
asset_id,
trip_id,
array_agg(geo_point)[safe_offset(0)] as origin,
array_reverse(array_agg(geo_point))[safe_offset(0)] as destination,
ST_MAKELINE(array_agg(geo_point order by ts)) as polyline ,
min(ts) as start_timestamp,
max(ts) as end_timestamp
from formatted
group by 1,2