I am new to coding. I want a logic that works on csv file. Lets say I am having a dataframe with a column name "label" and I wanted to have an output look like column "expected label".
print (df)
label
0 A
1 B
2 C
3 A
4 B
5 C
6 A
7 B
8 C
9 B
10 C
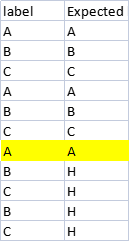
I need to find the last occurrence of the value "A" and replace other values (in this case "B" & "C" with "H") occurs only after the last occurrence. This is my code and don't know how to proceed after that.
last=df['labels']
max(loc for loc, val in enumerate(last) if val == 'A')
This gets me the last positional occurrence of "A". What I need is how to replace values after finding the last occurrence like I mentioned in the "expected label" column. I really appreciate the help.
CodePudding user response:
Use Series.cummax with swapped order in iloc[::-1] for False for all values after last A and set values in Series.where:
df['Expected'] = df['label'].where(df['label'].eq('A').iloc[::-1].cummax(),
df['label'].replace(to_replace =["B", "C"], value ="H"))
print (df)
label Expected
0 A A
1 B B
2 C C
3 A A
4 B B
5 C C
6 A A
7 B H
8 C H
9 B H
10 E E
Or:
df['Expected'] = df['label'].where(df['label'].eq('A').iloc[::-1].cummax() |
~df['label'].isin(['B','C']), 'H')
print (df)