I want to display the text file in my c program but nothing appears and the program just ended. I am using struct here. I previously used this kind of method, but now I am not sure why it isn't working. I hope someone could help me. Thanks a lot.
struct Records{
int ID;
string desc;
string supplier;
double price;
int quantity;
int rop;
string category;
string uom;
}record[50];
void inventory() {
int ID, quantity, rop;
string desc, supplier, category, uom;
double price;
ifstream file("sample inventory.txt");
if (file.fail()) {
cout << "Error opening records file." <<endl;
exit(1);
}
int i = 0;
while(! file.eof()){
file >> ID >> desc >> supplier >> price >> quantity >> rop >> category >> uom;
record[i].ID = ID;
record[i].desc = desc;
record[i].supplier = supplier;
record[i].price = price;
record[i].quantity = quantity;
record[i].rop = rop;
record[i].category = category;
record[i].uom = uom;
i ;
}
for (int a = 0; a < 15; a ) {
cout << "\n\t";
cout.width(10); cout << left << record[a].ID;
cout.width(10); cout << left << record[a].desc;
cout.width(10); cout << left << record[a].supplier;
cout.width(10); cout << left << record[a].price;
cout.width(10); cout << left << record[a].quantity;
cout.width(10); cout << left << record[a].rop;
cout.width(10); cout << left << record[a].category;
cout.width(10); cout << left << record[a].uom << endl;
}
file.close();
}
Here is the txt file:
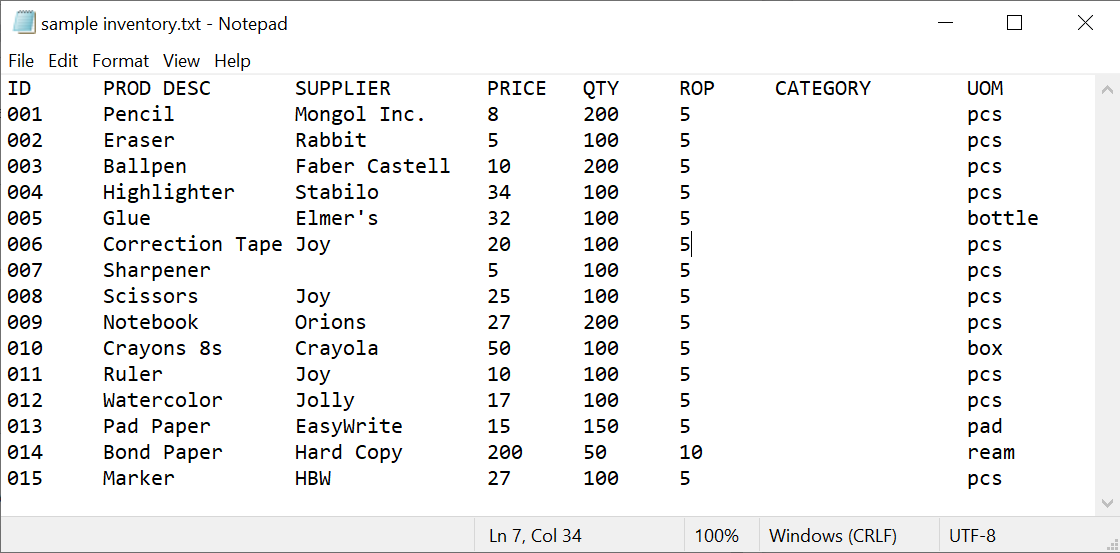
CodePudding user response:
Here are a couple of things you should consider.
- Declare the variables as you need them. Don’t declare them at the top of your function. It makes the code more readable.
- Use the file’s full path to avoid confusions. For instance
"c:/temp/sample inventory.txt". if ( ! file )is shorter.- To read data in a loop, use the actual read as a condition
while( file >> ID >>... ). This would have revealed the cause of your problem. - Read about the
setwmanipulator. file's destructor will close the stream - you don't need to callclose()
Your file format consists of a header and data. You do not read the header. You are trying to directly read the data. You try to match the header against various data types: strings, integers, floats; but the header is entirely made of words. Your attempt will invalidate the stream and all subsequent reading attempts will fail. So, first discard the header – you may use getline.
Some columns contain data consisting of more than one word. file >> supplier reads one word, not two or more. So you will get "Mongol", not "Mongol Inc." Your data format needs a separator between columns. Otherwise you won’t be able to tell where the column ends. If you add a separator, again, you may use getline to read fields.
The CATEGORY column is empty. Trying to read it will result in reading from a different column. Adding a separator will also solve the empty category column problem.
This is how your first rows will look like if you use comma as separator:
ID,PROD DESC,SUPPLIER,PRICE,QTY,ROP,CATEGORY,UOM
001,Pencil,Mongol Inc.,8,200,5,,pcs
A different format solution would be to define a string as a zero or more characters enclosed in quotes:
001 "Pencil" "Mongol Inc." 8 200 5 "" "pcs"
and take advantage of the quoted manipulator (note the empty category string):
const int max_records_count = 50;
Record records[max_records_count];
istream& read_record(istream& is, Record& r) // returns the read record in r
{
return is >> r.ID >> quoted(r.desc) >> quoted(r.supplier) >> r.price >> r.quantity >> r.rop >> quoted(r.category) >> quoted(r.uom);
}
istream& read_inventory(istream& is, int& i) // returns the number of read records in i
{
//...
for (i = 0; i < max_records_count && read_record(is, records[i]); i)
; // no operation
return is;
}
CodePudding user response:
Unfortunately you text file is not a typical CSV file, delimited by some character like a comma or such. The entries in the lines seem to be separated by tabs. But this is a guess by me. Anyway. The structure of the source file makes it harder to read.
Additionally, the file has an header and while reading the first line andtry to read the word "ID" into an int variable, this conversion will fail. The failbit of the stream is set, and from then on all further access to any iostream function for this stream will do nothing any longer. It will ignore all your further requests to read something.
Additional difficulty is that you have spaces in data fields. But the extractor operator for formatted input >> will stop, if it sees a white space. So, maybe only read half of the field in a record.
Solution: You must first read the header file, then the data rows. Next, you must know if the file is really tab separated. Sometimes tabs are converted to spaces. In that case, we would need to recreate the start position of a field in the a record.
In any case, you need to read a complete line, and after that split it in parts.
For the first solution approach, I assume tab separated fields.
One of many possible examples:
#include <iostream>
#include <string>
#include <fstream>
#include <sstream>
#include <vector>
#include <iomanip>
const std::string fileName{"r:\\sample inventory.txt"};
struct Record {
int ID;
std::string desc;
std::string supplier;
double price;
int quantity;
int rop;
std::string category;
std::string uom;
};
using Database = std::vector<Record>;
int main() {
// Open the source text file with inventory data and check, if it could be opened
if (std::ifstream ifs{ fileName }; ifs) {
// Here we will store all data
Database database{};
// Read the first header line and throw it away
std::string line{};
std::string header{};
if (std::getline(ifs, header)) {
// Now read all lines containing record data
while (std::getline(ifs, line)) {
// Now, we read a line and can split it into substrings. Assuming the tab as delimiter
// To be able to extract data from the textfile, we will put the line into a std::istrringstream
std::istringstream iss{ line };
// One Record
Record record{};
std::string field{};
// Read fields and put in record
if (std::getline(iss, field, '\t')) record.ID = std::stoi(field);
if (std::getline(iss, field, '\t')) record.desc = field;
if (std::getline(iss, field, '\t')) record.supplier = field;
if (std::getline(iss, field, '\t')) record.price = std::stod(field);
if (std::getline(iss, field, '\t')) record.quantity = std::stoi(field);
if (std::getline(iss, field, '\t')) record.rop = std::stoi(field);
if (std::getline(iss, field, '\t')) record.category = field;
if (std::getline(iss, field)) record.uom = field;
database.push_back(record);
}
// Now we read the complete database
// Show some debug output.
std::cout << "\n\nDatabase:\n\n\n";
// Show all records
for (const Record& r : database)
std::cout << std::left << std::setw(7) << r.ID << std::setw(20) << r.desc
<< std::setw(20) << r.supplier << std::setw(8) << r.price << std::setw(7)
<< r.quantity << std::setw(8) << r.rop << std::setw(20) << r.category << std::setw(8) << r.uom << '\n';
}
}
else std::cerr << "\nError: COuld not open source file '" << fileName << "'\n\n";
}
But to be honest, there are many assumptions. And tab handling is notoriously error prone.
So, let us make the next approach and extract the data according to their position in the header string. So, we will check, where each header string starts and use this information to later split a complete line into substrings.
We will use a list of Field Descriptors and search for their start position and width in the header line.
Example:
#include <iostream>
#include <string>
#include <fstream>
#include <sstream>
#include <vector>
#include <iomanip>
#include <array>
const std::string fileName{"r:\\sample inventory.txt"};
struct Record {
int ID;
std::string desc;
std::string supplier;
double price;
int quantity;
int rop;
std::string category;
std::string uom;
};
constexpr size_t NumberOfFieldsInRecord = 8u;
using Database = std::vector<Record>;
int main() {
// Open the source text file with inventory data and check, if it could be opened
if (std::ifstream ifs{ fileName }; ifs) {
// Here we will store all data
Database database{};
// Read the first header line and throw it away
std::string line{};
std::string header{};
if (std::getline(ifs, header)) {
// Analyse the header
// We have 8 elements in one record. We will store the positions of header items
std::array<size_t, NumberOfFieldsInRecord> startPosition{};
std::array<size_t, NumberOfFieldsInRecord> fieldWidth{};
const std::array<std::string, NumberOfFieldsInRecord> expectedHeaderNames{ "ID","PROD DESC","SUPPLIER","PRICE","QTY","ROP","CATEGORY","UOM"};
for (size_t k{}; k < NumberOfFieldsInRecord; k)
startPosition[k] = header.find(expectedHeaderNames[k]);
for (size_t k{ 1 }; k < NumberOfFieldsInRecord; k)
fieldWidth[k - 1] = startPosition[k] - startPosition[k - 1];
fieldWidth[NumberOfFieldsInRecord - 1] = header.length() - startPosition[NumberOfFieldsInRecord - 1];
// Now read all lines containing record data
while (std::getline(ifs, line)) {
// Now, we read a line and can split it into substrings. Based on poisition and field width
// To be able to extract data from the textfile, we will put the line into a std::istrringstream
std::istringstream iss{ line };
// One Record
Record record{};
std::string field{};
// Read fields and put in record
field = line.substr(startPosition[0], fieldWidth[0]); record.ID = std::stoi(field);
field = line.substr(startPosition[1], fieldWidth[1]); record.desc = field;
field = line.substr(startPosition[2], fieldWidth[2]); record.supplier = field;
field = line.substr(startPosition[3], fieldWidth[3]); record.price = std::stod(field);
field = line.substr(startPosition[4], fieldWidth[4]); record.quantity = std::stoi(field);
field = line.substr(startPosition[5], fieldWidth[5]); record.rop = std::stoi(field);
field = line.substr(startPosition[6], fieldWidth[6]); record.category = field;
field = line.substr(startPosition[7], fieldWidth[7]); record.uom = field;
database.push_back(record);
}
// Now we read the complete database
// Show some debug output.
std::cout << "\n\nDatabase:\n\n\n";
// Header
for (size_t k{}; k < NumberOfFieldsInRecord; k)
std::cout << std::left << std::setw(fieldWidth[k]) << expectedHeaderNames[k];
std::cout << '\n';
// Show all records
for (const Record& r : database)
std::cout << std::left << std::setw(fieldWidth[0]) << r.ID << std::setw(fieldWidth[1]) << r.desc
<< std::setw(fieldWidth[2]) << r.supplier << std::setw(fieldWidth[3]) << r.price << std::setw(fieldWidth[4])
<< r.quantity << std::setw(fieldWidth[5]) << r.rop << std::setw(fieldWidth[6]) << r.category << std::setw(fieldWidth[7]) << r.uom << '\n';
}
}
else std::cerr << "\nError: COuld not open source file '" << fileName << "'\n\n";
}
But this is still not all.
We should wrap all functions belonging to a record into the struct Record. And the same for the data base. And espcially we want to overwrite the extractor and the inserter operator. Then input and output will later be very simple.
We will save this for later . . .
If you can give more and better information regarding the structure of the source file, then I will update my answer.