Input data, transaction history in JSON files:
{"customer_id": "C1", "basket": [{"product_id": "P3", "price": 506}, {"product_id": "P4", "price": 121}], "date_of_purchase": "2018-09-01 11:09:00"}
{"customer_id": "C27", "basket": [{"product_id": "P57", "price": 154}, {"product_id": "P42", "price": 349}, {"product_id": "P47", "price": 180}], "date_of_purchase": "2021-09-06 04:52:08.505909"}
{"customer_id": "C1", "basket": [{"product_id": "P3", "price": 506}, {"product_id": "P4", "price": 121}], "date_of_purchase": "2018-10-01 11:09:00"}
Dataframe:
customer_id basket date_of_purchase
0 C4 [{'product_id': 'P31', 'price': 26}] 2021-09-06 05:47:08.505909
1 C13 [{'product_id': 'P36', 'price': 566}] 2021-09-06 03:52:08.505909
2 C15 [{'product_id': 'P02', 'price': 839}] 2021-09-06 05:48:08.505909
3 C22 [{'product_id': 'P37', 'price': 1235}] 2021-09-05 20:52:08.505909
4 C27 [{'product_id': 'P57', 'price': 154}, {'produc... 2021-09-06 04:52:08.505909
My code to read the JSON into a dataframe:
def read_json_folder(json_folder: str):
transactions_files = glob.glob("{}*/*.json".format(json_folder))
return pandas.concat(pandas.read_json(tf, lines=True) for tf in transactions_files)
For each transaction I want the customer ID and how many times they bought a specific product.
Expected output:
customer_id product_id purchase_count
C1 P2 11
C1 P3 5
C2 P9 7
CodePudding user response:
Build a dataframe from data
- read_json with lines argument
- explode the basket list by basket 'lines'
- decompose product information in product ids and prices
- drop unneeded columns
Build result dataframe from df
- groupby and count
- rename the count column
>>>TESTDATA="""
...{"customer_id": "C1", "basket": [{"product_id": "P3", "price": 506}, {"product_id": "P4", "price": 121}], "date_of_purchase": "2018-09-01 11:09:00"}
...{"customer_id": "C27", "basket": [{"product_id": "P57", "price": 154}, {"product_id": "P42", "price": 349}, {"product_id": "P47", "price": 180}], "date_of_purchase": "2021-09-06 04:52:08.505909"}
...{"customer_id": "C1", "basket": [{"product_id": "P3", "price": 506}, {"product_id": "P4", "price": 121}], "date_of_purchase": "2018-10-01 11:09:00"}
..."""
>>>df = pd.read_json(TESTDATA, lines=True)
>>>df = df.explode('basket')
>>>df[['product_id', 'price']] = df['basket'].apply(pd.Series)
>>>df.drop(['basket', 'price'], axis=1, inplace=True)
>>>df2 = df.groupby(['customer_id', 'product_id'], as_index=False).count()
>>>df2.rename(columns={'date_of_purchase': 'purchase_count'}, inplace=True)
>>>df2
customer_id product_id purchase_count
0 C1 P3 2
1 C1 P4 2
2 C27 P42 1
3 C27 P47 1
4 C27 P57 1
CodePudding user response:
If your Dataframe be like this:
shop_list = [
{"customer_id": "C1", "basket": [{"product_id": "P3", "price": 506}, {"product_id": "P4", "price": 121}], "date_of_purchase": "2018-09-01 11:09:00"},
{"customer_id": "C27", "basket": [{"product_id": "P57", "price": 154}, {"product_id": "P42", "price": 349}, {"product_id": "P47", "price": 180}], "date_of_purchase": "2021-09-06 04:52:08.505909"},
{"customer_id": "C1", "basket": [{"product_id": "P3", "price": 506}, {"product_id": "P4", "price": 121}], "date_of_purchase": "2018-10-01 11:09:00"}
]
shop = pd.DataFrame(shop_list)
let first get all product perches for each customer
costumer_gruopby = shop.groupby('customer_id')['basket'].apply(list).to_dict()
for k in costumer_gruopby.keys():
costumer_gruopby[k] = [item['product_id'] for sublist in costumer_gruopby[k] for item in sublist]
output:
#{'C1': ['P3', 'P4', 'P3', 'P4'], 'C27': ['P57', 'P42', 'P47']}
then create the result table:
table= pd.DataFrame(columns=['customer_id', 'product_id', 'purchase_count'])
for costumer,value in costumer_gruopby.items():
items = set(value)
for item in items:
table= table.append({'customer_id':costumer, 'product_id':item, 'purchase_count':value.count(item)}, ignore_index=True)
final result:
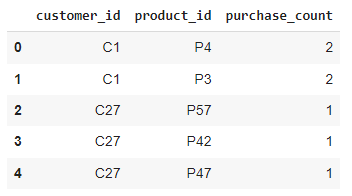
CodePudding user response:
Try this:
purchase_counts = df.groupby(['customer_id', 'product_id'], as_index=False).count()
Output:
>>> purchase_counts
customer_id product_id price
0 C1 P3 2
1 C1 P4 2
2 C27 P42 1
3 C27 P47 1
4 C27 P57 1