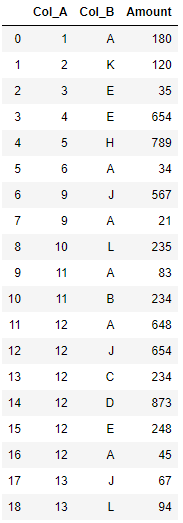
Sample Dataset (Note that each combination of Col_A and Col_B is unique):
import pandas as pd
d = {'Col_A': [1,2,3,4,5,6,9,9,10,11,11,12,12,12,12,12,12,13,13],
'Col_B': ['A','K','E','E','H','A','J','A','L','A','B','A','J','C','D','E','A','J','L'],
'Value':[180,120,35,654,789,34,567,21,235,83,234,648,654,234,873,248,45,67,94]
}
df = pd.DataFrame(data=d)
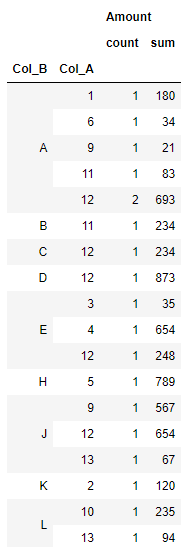
The requirement is to generate a table with each Col_B's amount, Col_A's counts, and total amount per Col_A. Show the categories in Col_B in descending order by their total amount.
This is what I have so far:
df.groupby(['Col_B','Col_A']).agg(['count','sum'])
The output would look like this. However, I'd like to add subtotals for each Col_B category and rank those subtotal categories in descending order so that it fulfills the requirement of getting each Col_B's amount.
Thanks in advance, everyone!
CodePudding user response:
The expected result is not clear for me but is it what your are looking for?
piv = df.groupby(['Col_B', 'Col_A'])['Amount'].agg(['count','sum']).reset_index()
tot = piv.groupby('Col_B', as_index=False).sum().assign(Col_A='Total')
cat = pd.CategoricalDtype(tot.sort_values('sum')['Col_B'], ordered=True)
out = pd.concat([piv, tot]).astype({'Col_B': cat}) \
.sort_values('Col_B', ascending=False, kind='mergesort') \
.set_index(['Col_B', 'Col_A'])
>>> out
count sum
Col_B Col_A
J 9 1 567
12 1 654
13 1 67
Total 3 1288
A 1 1 180
6 1 34
9 1 21
11 1 83
12 2 693
Total 6 1011
E 3 1 35
4 1 654
12 1 248
Total 3 937
D 12 1 873
Total 1 873
H 5 1 789
Total 1 789
L 10 1 235
13 1 94
Total 2 329
C 12 1 234
Total 1 234
B 11 1 234
Total 1 234
K 2 1 120
Total 1 120