I have a dataset similar to the following:
import pandas as pd
data = {'Country': ['Spain', 'Italy', 'France', 'Germany', 'Portugal', 'Greece', 'UK', 'Spain', 'Italy', 'France', 'Germany', 'Portugal', 'Greece', 'UK', 'Spain', 'Italy', 'France', 'Germany', 'Portugal', 'Greece', 'UK'],
'Date': ['Jan 2020', 'Jan 2020', 'Jan 2020', 'Jan 2020', 'Jan 2020', 'Jan 2020', 'Jan 2020', 'Feb 2020', 'Feb 2020', 'Feb 2020', 'Feb 2020', 'Feb 2020', 'Feb 2020', 'Feb 2020', 'Dec 2020', 'Dec 2020', 'Dec 2020', 'Dec 2020', 'Dec 2020', 'Dec 2020', 'Dec 2020'],
'Sales': [20000, 30000, 10000, 10000, 30000, 10000, 10000, 50000, 40000, 30000, 20000, 30000, 10000, 10000, 60000, 70000, 80000, 10000, 30000, 10000, 10000]}
df = pd.DataFrame(data)
Country Date Sales
0 Spain Jan 2020 20000
1 Italy Jan 2020 30000
2 France Jan 2020 10000
3 Germany Jan 2020 10000
4 Portugal Jan 2020 30000
5 Greece Jan 2020 10000
6 UK Jan 2020 10000
7 Spain Feb 2020 50000
8 Italy Feb 2020 40000
9 France Feb 2020 30000
10 Germany Feb 2020 20000
11 Portugal Feb 2020 30000
12 Greece Feb 2020 10000
13 UK Feb 2020 10000
14 Spain Dec 2020 60000
15 Italy Dec 2020 70000
16 France Dec 2020 80000
17 Germany Dec 2020 10000
18 Portugal Dec 2020 30000
19 Greece Dec 2020 10000
20 UK Dec 2020 10000
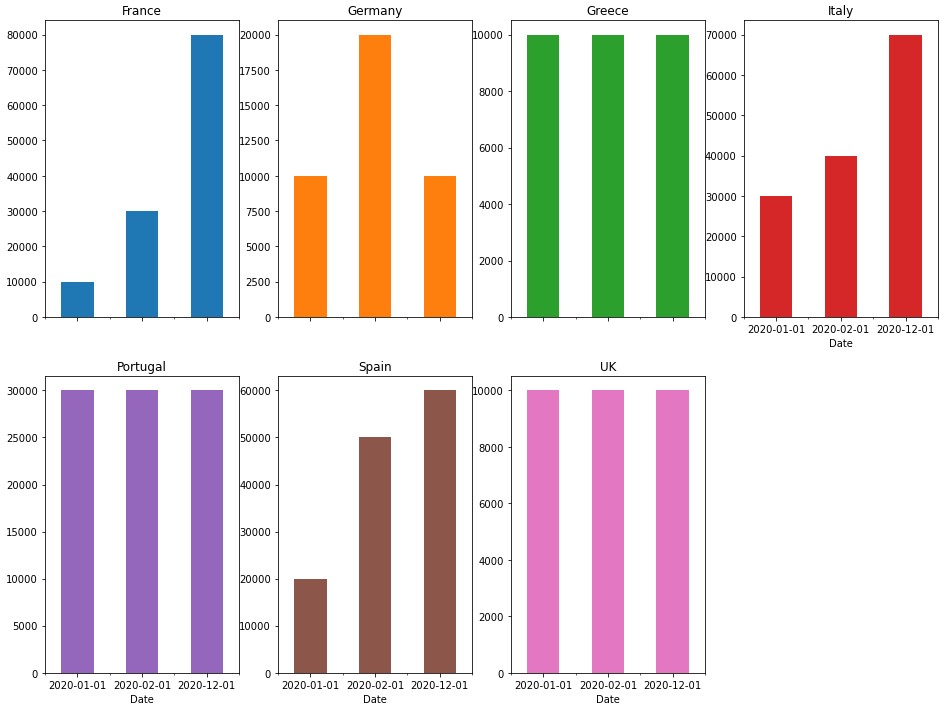
I would like to visualize how the Sales varied over the year by Country therefore I would like to show 7 histograms (one for each Country). For each plot, the 'Date' will be on the x-axis and the 'Sales' values on the y-axis. Also, a title to identify the Country is required as well as the x-label, y-label.
I have tried several options found in previous discussions but none of those works with what I want to achieve. I have tried the following:
df.groupby('Country').hist(column='Sales', grid= False, figsize=(2,2))
df['Sales'].hist(grid=True, by=one_year_df['Country'])
df.groupby('Country').hist(grid= False, figsize=(2,2))
df.reset_index().pivot('index','Country','Sales').hist(grid=False, bins=12)
grouped = df.groupby('Country')
ncols=2
nrows = int(np.ceil(grouped.ngroups/ncols))
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(12,12), sharey=False)
for (key, ax) in zip(grouped.groups.keys(), axes.flatten()):
grouped.get_group(key).plot(ax=ax)
ax.legend()
plt.show()
However, none of these options gives me the possibility to set the 'Date' column, also it seems that it is not possible to set the x-axis, y-axis as I wish and as a result, the plots are meaningless.
I have also found another piece of code that seems to consider all the variables but the result still is not as expected:
fig, ax = plt.subplots(figsize=(15,7))
df.groupby(['Country']).sum()['Sales'].plot(ax=ax)
ax.set_xlabel('Date')
ax.set_ylabel('Sales')
Any comments or suggestions are welcome. Thank you.
CodePudding user response:
- For each plot, the 'Date' will be on the x-axis and the 'Sales' values on the y-axis. is best shown with a line or bar plot. A histogram is essentially a bar plot (in terms of a visulization).
- Convert the
'Date'column to datetime with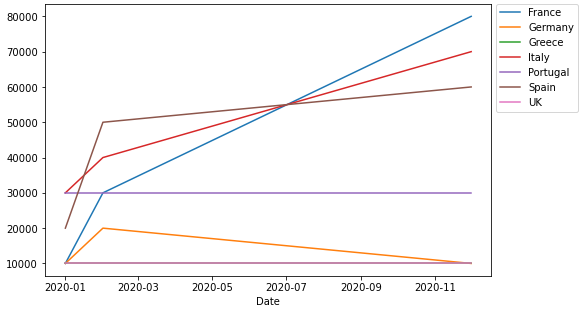
- If you plot a bar plot, there will be a crowded mess, because there will be a bar for each row of data.
ax = dfp.plot(kind='bar', subplots=True, figsize=(14, 12), layout=(2, 4), rot=0, legend=False)