I am trying to scrape NASDAQ's website for real time stock quotes. When I use chrome developer tools, I can see the span I want to target is (for example with Alphabet as of writing this) <span >$2952.77</span>. I want to extract the $2952.77. My python code is:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
s = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=s)
def get_last_price(ticker):
driver.get(f"https://www.nasdaq.com/market-activity/stocks/{ticker}")
price = driver.find_element(By.CLASS_NAME, "symbol-page-header__pricing-last-price")
print(price.get_attribute('text'))
# p = price.get_attribute('innerHTML')
get_last_price('googl')
The above code returns 'None'. If you uncomment out the line defining p and print it's output, it shows that Selenium thinks the span is empty.
<span ></span>
I don't understand why this is happening. My thought is that it has something to do with the fact that it's probably being rendered dynamically with Javascript, but I thought that was an advantage of Selenium say as opposed to BeautifulSoup... there shouldn't be an issue right?
CodePudding user response:
There are 2 nodes with the class symbol-page-header__pricing-price. The node that you want is under
<div ></div>
So, you need to get inside this div first to ensure you scrape the right one.
Anyways, I'd recommend you to use BeautifulSoup to scrape the HTML text after you’ve finished interacting with the dynamic website with selenium. This will save your time and your memory. It has no need to keep running the browser, so, it would be better if you terminate it (i.e. driver.close()) and use BeautifulSoup to explore the static HTML text.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
s = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=s)
def get_last_price(ticker):
driver.get(f"https://www.nasdaq.com/market-activity/stocks/{ticker}")
time.sleep(1)
driver.close()
soup = BeautifulSoup(driver.page_source, "lxml")
header = soup.find('div', attrs={'class': 'symbol-page-header__pricing-details symbol-page-header__pricing-details--current symbol-page-header__pricing-details--decrease'})
price = header.find('span', attrs={'class':'symbol-page-header__pricing-price'})
print(price)
print(price.text)
get_last_price('googl')
Output:
>>> <span >$2952.77</span>
>>> $2952.77
CodePudding user response:
If you look into the 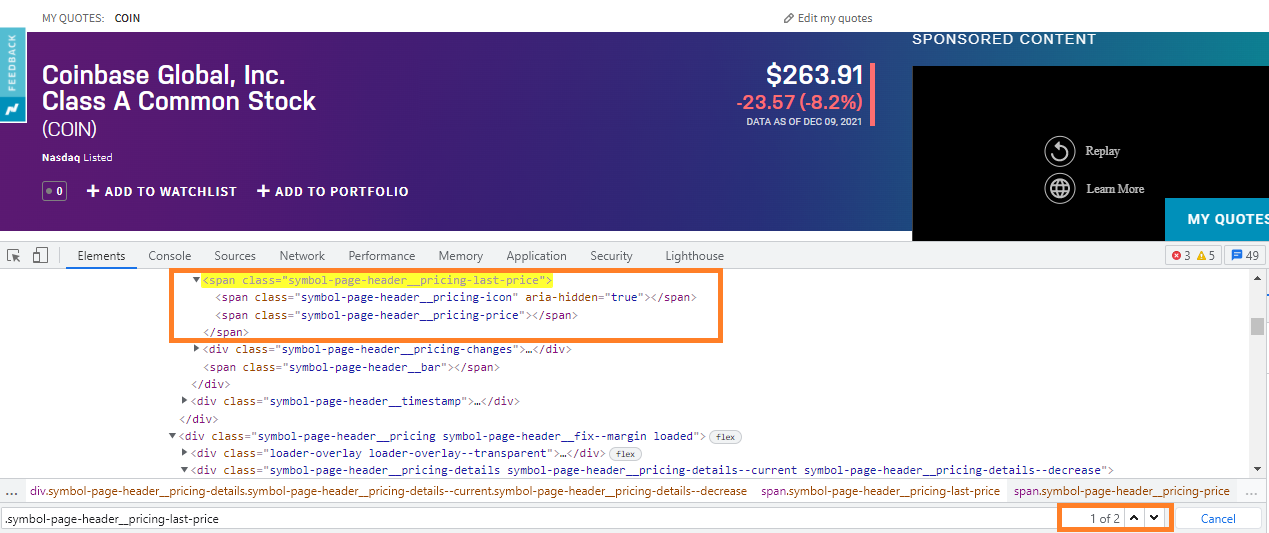
Solution
To print the price information you can use the following Locator Strategy:
Using XPATH and text attribute:
driver.get("https://www.nasdaq.com/market-activity/stocks/coin") print(WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH,"//span[@class='symbol-page-header__pricing-price' and text()]"))).text)Using XPATH and
get_attribute("innerHTML"):driver.get("https://www.nasdaq.com/market-activity/stocks/coin") print(WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH,"//span[@class='symbol-page-header__pricing-price' and text()]"))).get_attribute("innerHTML"))Console Output:
$263.91Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC