In a regression task of predicting 1 hour power load in the future using LSTM (univariate LSTM), the results can be plotted easily something like this:
plt.plot(y_ts, label='True Future', color='blue')
plt.plot(y_pred, label='Forecast', color='red')
plt.show()
This is because both y_ts and y_pred are 1D. Now, assuming that the task has changed to predict 6 hours power load in the future using LSTM. This means y_ts and y_pred are going to be now in 2D, for instance y_ts= (3454, 6) and y_pred= (3454, 6) How do I plot this case of high dimensional array?
CodePudding user response:
Fundamentally there is only one dimension in your data i.e. time; what you have are 6 time slices - it would make sense to append them to each other, plot on the same axes and mark each hour separately.
Let me explain this with the help of some fabricated data:
import numpy as np
from matplotlib import pyplot as plt
np.random.seed(42)
n, h = 3454, 6
y_ts, y_pred = np.random.randn(n, h).cumsum(), np.random.randn(n, h).cumsum()
y_ts = y_ts - np.min(y_ts)
y_pred = y_ts - (y_pred - np.min(y_pred)) / np.max(y_pred) * 0.05 * np.mean(y_ts)
y_ts = y_ts.reshape((n, h), order="F")
y_pred = y_pred.reshape((n, h), order="F")
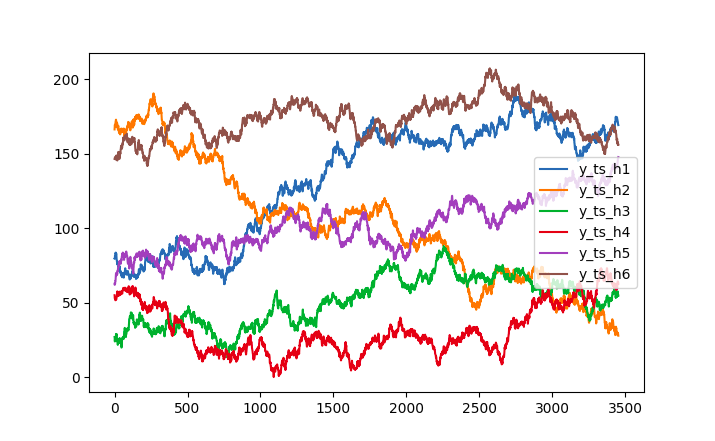
Plotting y_ts individually (and similarly for y_pred):
for i in range(h):
plt.plot(y_ts[:, i], label=f'y_ts_h{i 1}')
plt.legend()
plt.show()
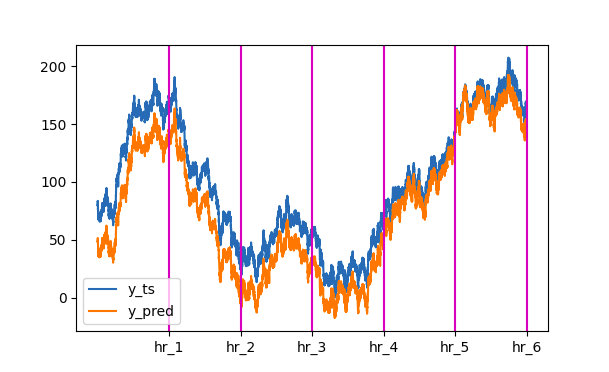
Now, you can straighten your data and plot it as a 1-D series as shown below:
y_ts = y_ts.reshape((n*h), order="F")
y_pred = y_pred.reshape((n*h), order="F")
plt.plot(y_ts, label=f'y_ts')
plt.plot(y_pred, label=f'y_pred')
for i in range(h):
plt.axvline(x=(n*(i 1)), c='m')
plt.xticks([(i 1)*n for i in range(h)], [f'hr_{i 1}' for i in range(h)])
plt.legend()
plt.show()