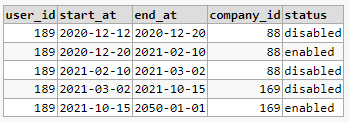
I've written two queries below with results that look similar to this:
table : company_changes
| user_id | start_at | end_at | company_id |
|---|---|---|---|
| 189 | 2020-12-12 | 2021-03-02 | 88 |
| 189 | 2021-03-02 | 2050-01-01 | 169 |
table: enablement_changes
| user_id | start_at | end_at | enablement |
|---|---|---|---|
| 189 | 2020-12-12 | 2021-10-15 | disabled |
| 189 | 2021-10-15 | 2050-01-01 | enabled |
It is important that I know when users are at a certain company_id and are either enabled or disabled.
My desired results are a table like this:
| user_id | start_at | end_at | company_id | status |
|---|---|---|---|---|
| 189 | 2020-12-12 | 2021-03-02 | 88 | disabled |
| 189 | 2021-03-02 | 2021-10-15 | 169 | disabled |
| 189 | 2021-10-15 | 2050-01-01 | 169 | enabled |
I essentially want to combine the results of those queries together. The 2050-01-01 is an arbitrary date in the future. Since the user_id has not changed status or company_id then it shows as 2050-01-01 because it is the user's present state.
Any idea how to approach this?
Here is the fiddle: 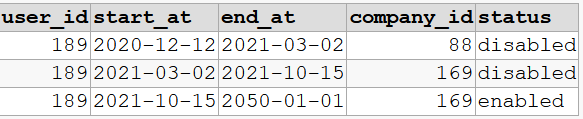
CodePudding user response:
Lukasz solution is good.
The but will match rows where the c table end time matches the start time of e table. Often datetime ranges want to be inclusive of start but not matching on end otherwise you will get two rows.
And it will miss any joins where the c start and end after the e table rows, but you want a match of the sub set. This latter point depend on if you are doing a dense match (there are always rows for all time) or a sparse match (only rows for some of the time)
The first problem can be fixed with an extra check:
SELECT c.user_id
,GREATEST(c.start_at, e.start_at) AS start_at
,LEAST(c.end_at, e.end_at) AS end_at
,c.company_id
,e.status
FROM company_changes c
JOIN enablement_changes e
ON (c.start_at BETWEEN e.start_at AND e.end_at AND c.start_at < e.end_at
OR c.end_at BETWEEN e.start_at AND e.end_at AND c.end_at > e.start_at )
AND c.user_id = e.user_id
ORDER BY 1,2;
Where-as to match sparse matches you need.
SELECT c.user_id
,GREATEST(c.start_at, e.start_at) AS start_at
,LEAST(c.end_at, e.end_at) AS end_at
,c.company_id
,e.status
FROM company_changes c
JOIN enablement_changes e
ON c.user_id = e.user_id
AND (c.end_at > e.start AND c.start_at < e.end_at)
ORDER BY 1,2;
On really large tables with large ranges the later code can be costly
CodePudding user response:
If in practice you have more complicated data and there may be overlapping time intervals, for example:
table: enablement_changes
| user_id | start_at | end_at | enablement |
|---|---|---|---|
| 189 | 2020-12-12 | 2021-10-15 | disabled |
| 189 | 2020-12-20 | 2021-02-10 | enabled |
| 189 | 2021-10-15 | 2050-01-01 | enabled |
I recommend a more complex solution:
WITH _k AS (
SELECT 1 AS n
UNION ALL
SELECT 2 AS n
), _points AS (
SELECT user_id, CASE WHEN n = 1 THEN start_at ELSE end_at END AS date_point, n
FROM company_changes
CROSS JOIN _k
UNION
SELECT user_id, CASE WHEN n = 1 THEN start_at ELSE end_at END AS date_point, n
FROM enablement_changes
CROSS JOIN _k
), _drank AS (
SELECT p.user_id, p.date_point, DENSE_RANK() OVER(PARTITION BY p.user_id ORDER BY p.date_point) AS dr
FROM _points AS p
GROUP BY p.user_id, p.date_point
)
SELECT d1.user_id, d1.date_point AS start_at, d2.date_point AS end_at, c.company_id, MAX(s.status) AS status -- or MIN if status disabled is stronger than enabled in the same time
FROM _drank AS d1
JOIN _drank AS d2 ON d1.dr = d2.dr-1 AND d1.user_id = d2.user_id
LEFT JOIN company_changes AS c ON d1.user_id = c.user_id AND d1.date_point < c.end_at AND c.start_at < d2.date_point
LEFT JOIN enablement_changes AS s ON d1.user_id = s.user_id AND d1.date_point < s.end_at AND s.start_at < d2.date_point
GROUP BY d1.user_id, d1.date_point, d2.date_point, c.company_id
ORDER BY 1,2,3;