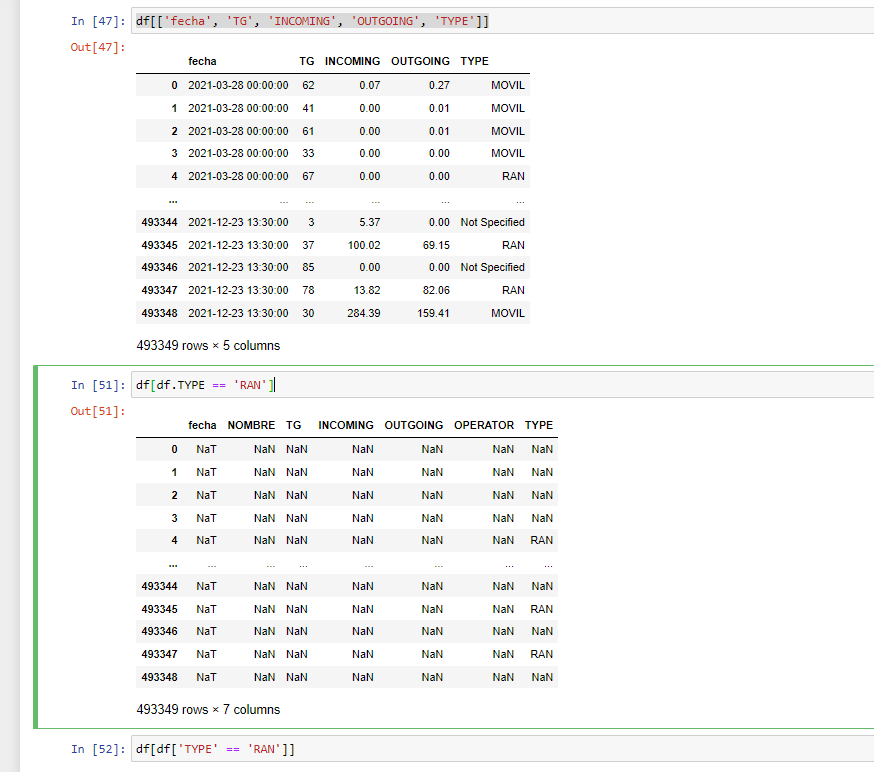
can someone tell me why filtering a dataframe based on a column value does not apply the filter, instead it fills the other columns with nan values, as the following pictures show
CodePudding user response:
To test a column for NaN, use isna(). See example below. Hope this is helpful, please leave a comment if something doesn't work
import pandas as pd
df = pd.DataFrame(data={"col1": [1,2], "col2": ["three",float('nan')]})
df[df.col2.isna()]
Output
| col1 | col2 | |
|---|---|---|
| 1 | 2 | nan |
CodePudding user response:
Please don't link images to external sources, and use code blocks. Easily accessible data in questions is critical to reproducing the problem.
import numpy as np
import pandas as pd
dates = pd.date_range("20211223", periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
print(f"{df[df['A'] > 1]}")
You were mostly on the right track. Instead on df[df['TYPE' == 'RNA']] you should use df[df['TYPE'] == 'RNA']