I have a pandas dataframe as such:
id =[30,30,40,40,30,40,55,30]
month =[1,3,11,4,10,2,12,12]
average=[90,80,50,92,18,15,16,55]
sec =['id1','id1','id3','id4','id2','id2','id1','id1']
df = pd.DataFrame(list(zip(id,sec,month,average)),columns =['id','sec','month','Average'])
We want to add one more column having comma separated months of below conditions
- Need to exclude id2 sec
- and below 90 average
Desired Output
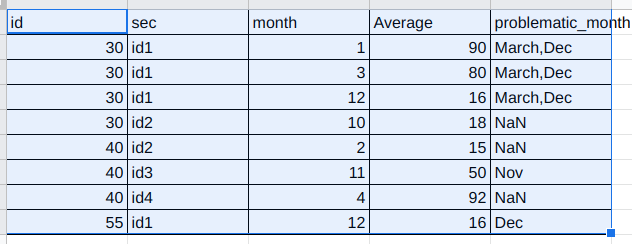
I have tried below code but not getting desired output
final=pd.DataFrame()
for i in set(sec):
if i !='id2': #Exclude id2
d2 =df[df['sec']==i]
d2=df[df['average']<90] # apply below 90 condition
d2=d2[['id','month']].groupby(['id'], as_index=False).agg(lambda x: ', '.join(sorted(set(x.astype(str))))) #comma seperated data
d2.rename(columns={'month':'problematic_month'},inplace=True)
d2['sec']=i
tab =df.merge(d2,on =['id','sec'], how ='inner')
final =final.append(tab)
else:
d2 =df[df['sec']==i]
d2['problematic_month']=np.NaN
final =final.append(d2)
Kindly suggest any other way(without merge) to get the desired output
CodePudding user response:
You can start by first converting your int months to actual Month abbreviations using calendar.
df['month'] = df['month'].apply(lambda x: calendar.month_abbr[x])
print(df.head(3))
id sec month Average
0 30 id1 Jan 90
1 30 id1 Mar 80
2 40 id3 Nov 50
Then I would use loc to narrow your dataframe based on your conditions above and a groupby and to get your months together per sec.
Thereafter use map to attach it to your initial dataframe:
r = df.loc[(df['Average'].gt(90) |\
(df['sec'].eq('id2'))).eq(0)]\
.groupby('sec').agg({'month':lambda x: ','.join(x)})\
.reset_index()\
.rename({'month':'problematic_month'},axis=1)
print(r)
sec problematic_month
0 id1 Jan,Mar,Dec
1 id3 Nov
# Attach with map
df['problematic_month'] = df['sec'].map(dict(zip(r.sec,r.problematic_month)))
>>> print(df)
id sec month Average problematic_month
0 30 id1 Jan 90 Jan,Mar,Dec
1 30 id1 Mar 80 Jan,Mar,Dec
2 40 id3 Nov 50 Nov
3 40 id4 Apr 92 NaN
4 30 id2 Oct 18 NaN
5 40 id2 Feb 15 NaN
6 55 id1 Dec 16 Jan,Mar,Dec
Then using this problematic_month column, you can check whether it contains a , and it it does you can select the first and last column:
import numpy as np
f = df['problematic_month'].str.split(',').str[0]
l = ',' df['problematic_month'].str.split(',').str[-1]
df['problematic_month'] = np.where(df['problematic_month'].str.contains(','),f l, df['problematic_month'])
Answer:
>>> print(df)
id sec month Average problematic_month
0 30 id1 Jan 90 Jan,Dec
1 30 id1 Mar 80 Jan,Dec
2 40 id3 Nov 50 Nov
3 40 id4 Apr 92 NaN
4 30 id2 Oct 18 NaN
5 40 id2 Feb 15 NaN
6 55 id1 Dec 16 Jan,Dec
CodePudding user response:
Another way using groupby transform
import calendar
d = dict(enumerate(calendar.month_abbr))
s = df['month'].map(d).where(df['sec'].ne("id2")& (df['Average'].lt(90)))
col = s.groupby([df["id"],df['sec']]).transform(lambda x: ','.join(x.dropna()))
out = df.assign(problematic_column=col.replace("",np.nan)).sort_values(['id','sec'])
print(out)
id sec month Average problematic_column
0 30 id1 1 90 Mar,Dec
1 30 id1 3 80 Mar,Dec
7 30 id1 12 55 Mar,Dec
4 30 id2 10 18 NaN
5 40 id2 2 15 NaN
2 40 id3 11 50 Nov
3 40 id4 4 92 NaN
6 55 id1 12 16 Dec
Steps:
- Map the month column to the calender to get month abbreviation.
- Retain values only when the condition matches.
- Use groupby and transform to dropna and join by comma.