I have a .txt file having multiple nested headers (textual version down below)
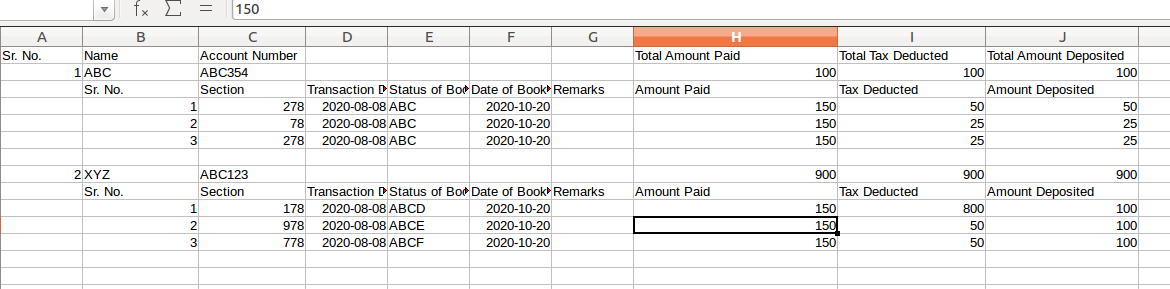
- The Sr.No. column is repeated in the outer as well as inner table
- The Inner table headers are repeated every time the outer Sr.No. Changes (For ex. here from Sr.N. from 1 to 2)
- There could be n number of rows for each inner table. I want to parse this and flatten this table such that the actual columns are (Name, Account Number,Sr. No., Section,Transaction Date,Status of Booking,Date of Booking,Remarks,Amount Paid,Tax Deducted,Amount Deposited).
I have tried using pandas read_csv function with multi header option
>>> pd.read_csv('sample.txt.csv', sep="^", header=[0],index_col=[0,1])
but that does not seems to help

Pardon any mistakes, this is my first question.Can provide more info
Sample Data (^ column divider):
Sr. No.^Name ^Account Number^^^^^Total Amount Paid^Total Tax Deducted^Total TDS Deposited
1^ABC^ABC354^^^^^100^100^100
^Sr. No.^Section^Transaction Date^Status of Booking^Date of Booking^Remarks^Amount Paid^Tax Deducted^TDS Deposited
^1^278^2020-08-08^ABC^2020-10-20^^150^1000^100
^2^78^2020-08-08^ABC^2020-10-20^^150^1000^100
^3^278^2020-08-08^ABC^2020-10-20^^150^1000^100
^^^^^^^^^
2^XYZ^ABC123^^^^^900^900^900
^Sr. No.^Section^Transaction Date^Status of Booking^Date of Booking^Remarks^Amount Paid^Tax Deducted^TDS Deposited
^1^178^2020-08-08^ABCD^2020-10-20^^150^1000^100
^2^978^2020-08-08^ABCE^2020-10-20^^150^1000^100
^3^778^2020-08-08^ABCF^2020-10-20^^150^1000^100
CodePudding user response:
Here is a more concise approach, which does the following:
- It splits the text file to extract the top header
- It creates a list of items by splitting the data on
^^^^^^^^^ - It then iterates all items and creates separate dataframes for the top and bottom parts
- It joins top and bottom dfs
- It concatenates all dfs to a single file
Example:
import pandas as pd
import io
# read file here, I'll proceed without it for the reproducibility of the answer
#with open('filename.csv') as f:
# data = f.read()
data = '''Sr. No.^Name ^Account Number^^^^^Total Amount Paid^Total Tax Deducted^Total TDS Deposited
1^ABC^ABC354^^^^^100^100^100
^Sr. No.^Section^Transaction Date^Status of Booking^Date of Booking^Remarks^Amount Paid^Tax Deducted^TDS Deposited
^1^278^2020-08-08^ABC^2020-10-20^^150^1000^100
^2^78^2020-08-08^ABC^2020-10-20^^150^1000^100
^3^278^2020-08-08^ABC^2020-10-20^^150^1000^100
^^^^^^^^^
2^XYZ^ABC123^^^^^900^900^900
^Sr. No.^Section^Transaction Date^Status of Booking^Date of Booking^Remarks^Amount Paid^Tax Deducted^TDS Deposited
^1^178^2020-08-08^ABCD^2020-10-20^^150^1000^100
^2^978^2020-08-08^ABCE^2020-10-20^^150^1000^100
^3^778^2020-08-08^ABCF^2020-10-20^^150^1000^100'''
headers, content = data.split('\n', 1)
content = [i.strip() for i in content.split('^^^^^^^^^')]
dfs = []
for i in content:
content_top, content_bottom = i.split('\n', 1)
df_top = pd.read_csv(io.StringIO(headers '\n' content_top), sep='^').dropna(axis=1, how='all')
top_data = headers '\n' content_top
df_bottom = pd.read_csv(io.StringIO(content_bottom), sep='^').dropna(axis=1, how='all')
df = df_bottom.join(df_top, lsuffix='_').fillna(method='ffill')
dfs.append(df)
final_df = pd.concat(dfs)
Output:
| Sr. No._ | Section | Transaction Date | Status of Booking | Date of Booking | Amount Paid | Tax Deducted | TDS Deposited | Sr. No. | Name | Account Number | Total Amount Paid | Total Tax Deducted | Total TDS Deposited | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 278 | 2020-08-08 | ABC | 2020-10-20 | 150 | 1000 | 100 | 1 | ABC | ABC354 | 100 | 100 | 100 |
| 1 | 2 | 78 | 2020-08-08 | ABC | 2020-10-20 | 150 | 1000 | 100 | 1 | ABC | ABC354 | 100 | 100 | 100 |
| 2 | 3 | 278 | 2020-08-08 | ABC | 2020-10-20 | 150 | 1000 | 100 | 1 | ABC | ABC354 | 100 | 100 | 100 |
| 0 | 1 | 178 | 2020-08-08 | ABCD | 2020-10-20 | 150 | 1000 | 100 | 2 | XYZ | ABC123 | 900 | 900 | 900 |
| 1 | 2 | 978 | 2020-08-08 | ABCE | 2020-10-20 | 150 | 1000 | 100 | 2 | XYZ | ABC123 | 900 | 900 | 900 |
| 2 | 3 | 778 | 2020-08-08 | ABCF | 2020-10-20 | 150 | 1000 | 100 | 2 | XYZ | ABC123 | 900 | 900 | 900 |
CodePudding user response:
If your data is well formed, you could transform it into something more readable by python. with 500k to 700k lines this should be done line wise - on block may be a bit memory hungry.
This code may work or this may also not be feasable if your file does not adhere to your shown structure:
Structure:
- outer header
- outer data (starts with number in col 0)
- inner header
- [inner data]
- empty line
- [outer header
- outer data (starts with number in col 0)
- inner header
- inner data
- empty line]
Demo file:
infile = "t.txt"
with open("t.txt","w") as f:
f.write("""Sr. No.^Name ^Account Number^^^^^Total Amount Paid^Total Tax Deducted^Total TDS Deposited
1^ABC^ABC354^^^^^100^100^100
^Sr. No.^Section^Transaction Date^Status of Booking^Date of Booking^Remarks^Amount Paid^Tax Deducted^TDS Deposited
^1^278^2020-08-08^ABC^2020-10-20^^150^1000^100
^2^78^2020-08-08^ABC^2020-10-20^^150^1000^100
^3^278^2020-08-08^ABC^2020-10-20^^150^1000^100
^^^^^^^^^
2^XYZ^ABC123^^^^^900^900^900
^Sr. No.^Section^Transaction Date^Status of Booking^Date of Booking^Remarks^Amount Paid^Tax Deducted^TDS Deposited
^1^178^2020-08-08^ABCD^2020-10-20^^150^1000^100
^2^978^2020-08-08^ABCE^2020-10-20^^150^1000^100
^3^778^2020-08-08^ABCF^2020-10-20^^150^1000^100""")
Code:
import csv
infile = "t.txt"
outfile = "processed.txt"
with open(infile) as f, open(outfile,"w", newline='') as out:
writer = csv.writer(out)
headers = ["outer " k if k.strip() else '' for k in next(f).strip().split("^")]
inner_header = []
outer_data = None
curr_data = []
for line in f:
line = line.strip().split("^")
if all(not l for l in line):
line = None # line is empty == end of an inner data block
if line and line[0]: # start of outer data block
outer_data = line[:]
curr_data = []
elif line and not inner_header: # 1st inner header
headers.extend(line)
writer.writerow(headers)
inner_header = line[:]
elif line and inner_header and all(
inner_header[i] == line[i] for i in range(len(line))):
# skip all other inner headers
continue
elif line: # inner data
curr_data.append(line[:])
else: # line == None => inner data done, write it
for cur in curr_data:
writer.writerow(outer_data cur)
curr_data = []
# last part of inner data, not yet written, no last empty line, write it
if curr_data:
# write it
for cur in curr_data:
writer.writerow(outer_data cur)
curr_data = []
Result (i did not see any point in using ^ instead of , - change it if you want):
outfile = "processed.txt"
with open(outfile) as f:
for l in f:
print(l, end = "")
outer Sr. No.,outer Name ,outer Account Number,,,,,outer Total Amount Paid,outer Total Tax Deducted,outer Total TDS Deposited,,Sr. No.,Section,Transaction Date,Status of Booking,Date of Booking,Remarks,Amount Paid,Tax Deducted,TDS Deposited
1,ABC,ABC354,,,,,100,100,100,,1,278,2020-08-08,ABC,2020-10-20,,150,1000,100
1,ABC,ABC354,,,,,100,100,100,,2,78,2020-08-08,ABC,2020-10-20,,150,1000,100
1,ABC,ABC354,,,,,100,100,100,,3,278,2020-08-08,ABC,2020-10-20,,150,1000,100
2,XYZ,ABC123,,,,,900,900,900,,1,178,2020-08-08,ABCD,2020-10-20,,150,1000,100
2,XYZ,ABC123,,,,,900,900,900,,2,978,2020-08-08,ABCE,2020-10-20,,150,1000,100
2,XYZ,ABC123,,,,,900,900,900,,3,778,2020-08-08,ABCF,2020-10-20,,150,1000,100
This cleaned file should be easily understood by pandas - you can drop any columns you do not want.