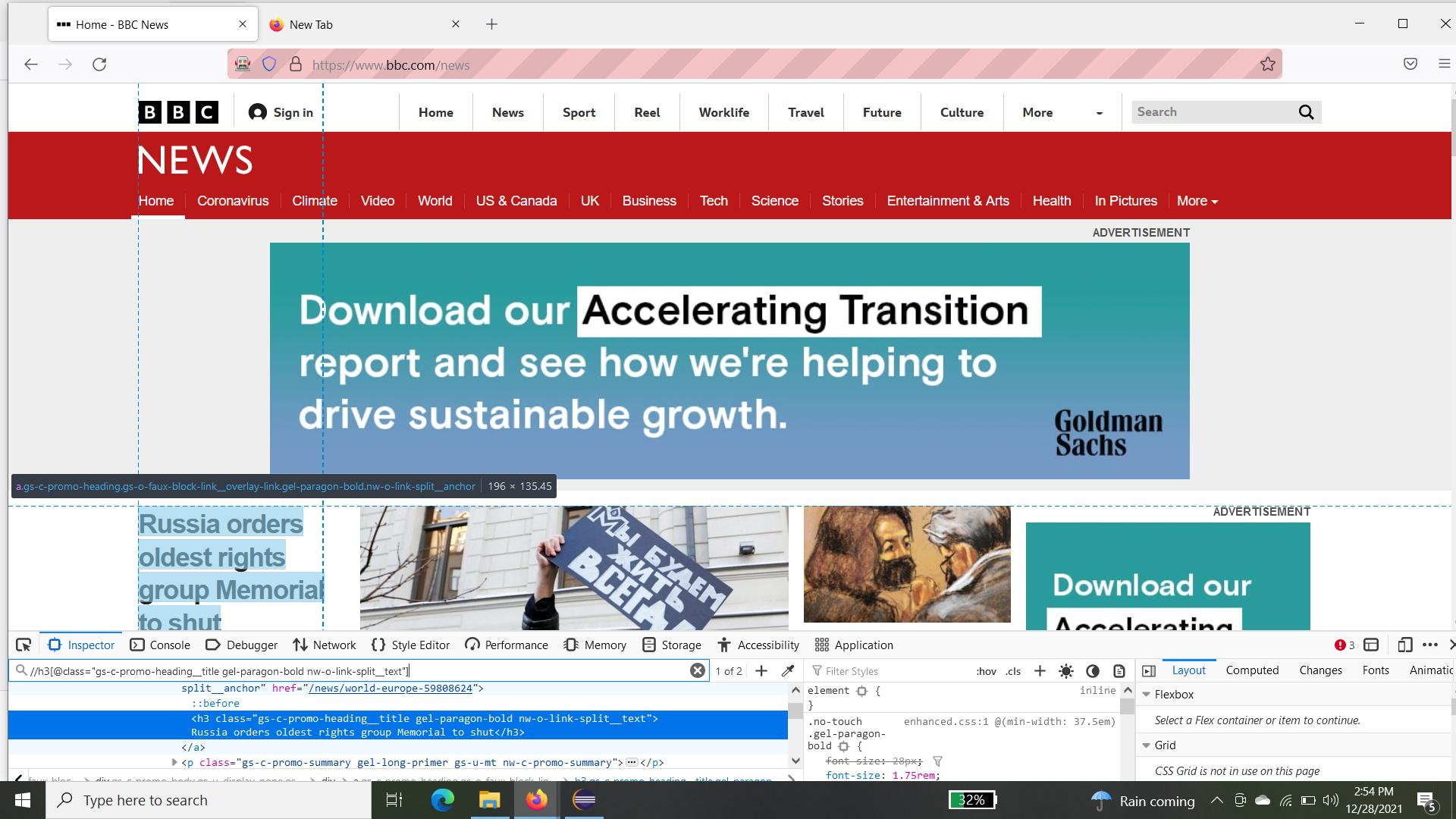
I am trying to navigate to each of the links and get their first news on the page.but can't get a unique xpath for the header info across all pages
Refer the attached pic, it shows 2 elements. how can i make it as unique to fetch only the header / title news.
CodePudding user response:
You can select only the first element by using the parent's first child and then point to the child element, for example:
//div/div[1]/div/a/h3[@]
[1] is equal to :first-child
CodePudding user response:
To retrieve the header of the first news you need to induce WebDriverWait for the visibilityOfElementLocated() and you can use either of the following Locator Strategies:
Java and xpath and
getText():System.out.println(new WebDriverWait(driver, 20).until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//div[contains(@class, 'gs-u-display-inline-block@m')]//h3[@class='gs-c-promo-heading__title gel-paragon-bold nw-o-link-split__text']"))).getText());Python and css_selector and text attribute:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div[class*='gs-u-display-inline-block@m'] h3.gs-c-promo-heading__title.gel-paragon-bold.nw-o-link-split__text"))).text)Console Output:
Russia orders oldest rights group Memorial to shutNote : For Python clients you have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
CodePudding user response:
There are many headers on that page and they are changing. I mean some news are coming and being removed from this page.
If you want to get all the news title texts you can get all the headers elements and then iterate over them and extract their texts.
Something like this:
List<WebElement> headers = driver.findElements(By.xpath("//h3[@class='gs-c-promo-heading__title gel-pica-bold nw-o-link-split__text']"));
for (WebElement header : headers){
((JavascriptExecutor) driver).executeScript("arguments[0].scrollIntoView(true);", header);
System.out.println(header.getText());
}