I'm trying to scrape a 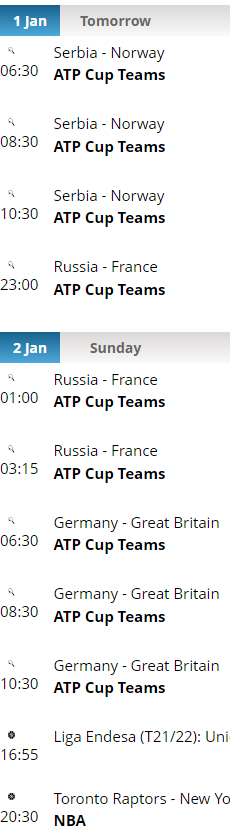
CodePudding user response:
How to achieve?
Change the approach of collecting your data a bit and select the elements in order they appear under the date seperators.
Step #1
Select all the date seperators:
soup.select('.dateSeparator')
Step #2
Iterate over each of them and all of its next siblings and break if the sibling is an <div>:
for item in date.find_next_siblings():
if item.name == 'div':
break
Step #3
Extract the texts with stripped_strings and make some adjustments, cause the structure is not always the same:
text = tuple(item.stripped_strings)
...
Step #4
Store the infromation in a list of dicts and create your dataframe.
pd.DataFrame(data)
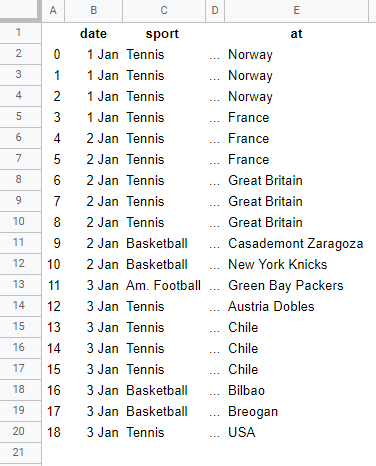
Example
Note: The output may be slightly different from the expected one, as I created it before you added the screenshot and I was shown the German website. However, the direction should be clear and the approach is to be adapted.
...
data = []
for date in soup.select('.dateSeparator'):
for item in date.find_next_siblings():
if item.name == 'div':
break
text = tuple(item.stripped_strings)
data.append({
'date':date.span.text.strip(),
'time':text[0],
'sport':text[1],
'at':text[3].split('-')[-1] if len(text) > 4 else text[3].split(':')[-1].split('-')[-1],
'teams':text[3] if len(text) > 4 else text[3].split(':')[-1],
'event':text[4] if len(text) > 4 else text[3].split(':')[0]
})
pd.DataFrame(data)
Output
| date | time | sport | at | teams | event |
|---|---|---|---|---|---|
| 1 Jan | 07:30 | Tennis | Norwegen | Serbien - Norwegen | ATP-Cup-Teams |
| ... | ... | ... | ... | ... | ... |
| 3 Jan | 21:30 | Basketball | Breogan | Obradoiro CAB - Breogan | ACB |