I'm writing a program to scrape through a folder of PDFs, extracting a table from each that contains the same data fields. Sample screenshot of the table in one of the PDFs:
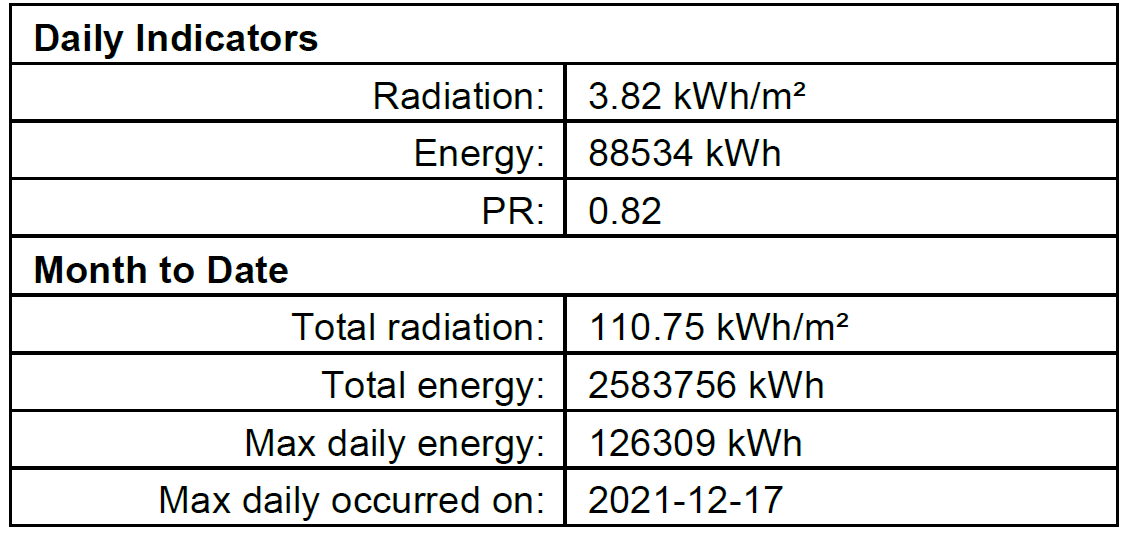
The goal of the program is to produce a spreadsheet with all of the data from each PDF in a single row with the date of the PDF, and the common fields as the column headers. The date in the first column should be the date in the PDF filename. It should look like this:
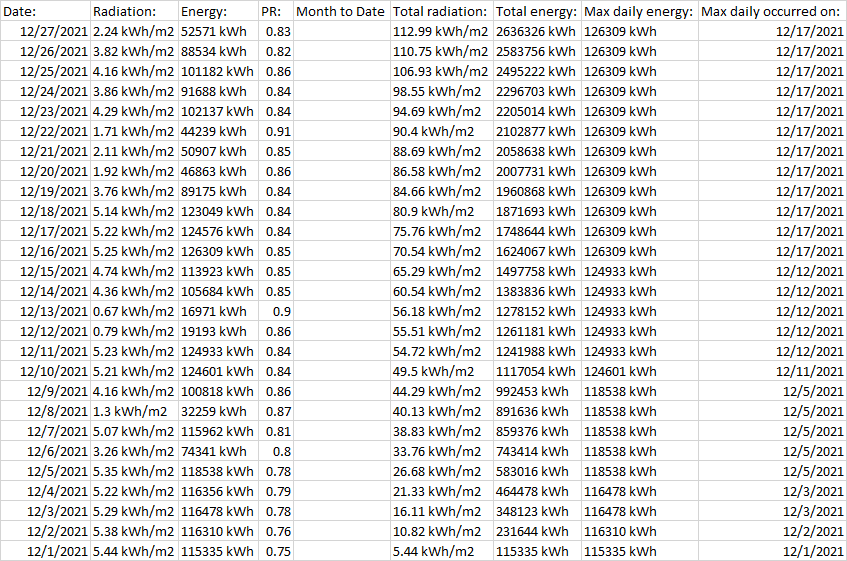
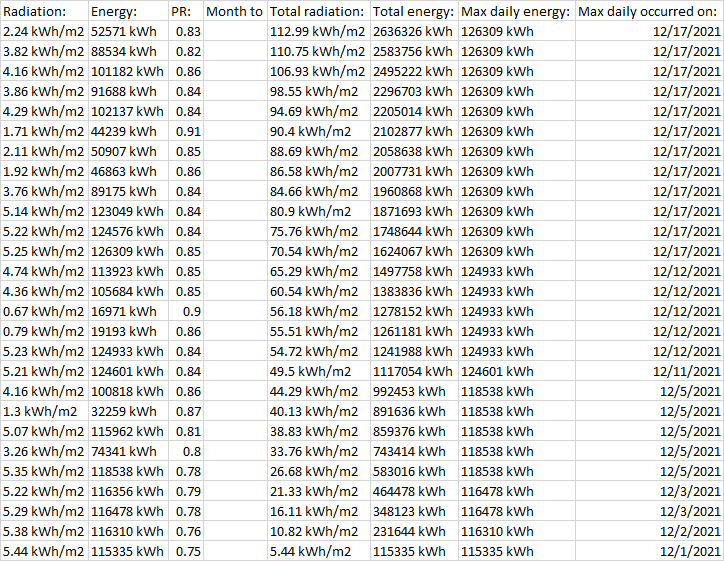
When I extract out the data into a dataframe and add column headers for "Field" and the date of the report, it looks like this:
Field 2021-12-04
0 Radiation: 5.22 kWh/m2
1 Energy: 116356 kWh
2 PR: 0.79
3 Month to Date NaN
4 Total radiation: 21.33 kWh/m2
5 Total energy: 464478 kWh
6 Max daily energy: 116478 kWh
7 Max daily occurred on: 2021-12-03
Then I set the index as the first column, since those are the common fields that I'll concat based on. When I do that, the date column header seems to be at a different level as the Field header? I'm not sure what happens here:
2021-12-20
Field
Radiation: 3.76 kWh/m2
Energy: 89175 kWh
PR: 0.84
Month to Date NaN
Total radiation: 84.66 kWh/m2
Total energy: 1960868 kWh
Max daily energy: 126309 kWh
Max daily occurred on: 2021-12-17
Then I transpose, and the result looks OK:
Field Radiation: Energy: ... Max daily energy: Max daily occurred on:
2021-12-13 0.79 kWh/m2 19193 kWh ... 124933 kWh 2021-12-12
Then I concatenate, and the result looks good except for some reason the first column with the dates is lost. Any suggestions?
import tabula as tb
import os
import glob
import pandas as pd
import datetime
import re
begin_time = datetime.datetime.now()
User_Profile = os.environ['USERPROFILE']
Canadian_Combined = User_Profile '\Combined.csv'
CanadianReportsPDF = User_Profile '\Canadian Reports (PDF)'
CanadianDailySummaryTable = (72,144,230,465)
CanadianDailyDF = pd.DataFrame()
def CanadianScrape():
global CanadianDailyDF
for pdf in glob.glob(CanadianReportsPDF '/*Daily*'):
# try:
dfs = tb.read_pdf(os.path.abspath(pdf), area=CanadianDailySummaryTable, lattice=True, pages=1)
df = dfs[0]
date = re.search("([0-9]{4}\-[0-9]{2}\-[0-9]{2})", pdf)
df.columns = ["Field",date.group(0)]
df.set_index("Field",inplace=True)
# print(df.columns)
print(df)
df_t = df.transpose()
# print(df_t)
CanadianDailyDF = pd.concat([df_t,CanadianDailyDF], ignore_index=False)
# print(CanadianDailyDF)
# except:
# continue
# print(CanadianDailyDF)
CanadianDailyDF.to_csv(Canadian_Combined, index=False)
CanadianScrape()
print(datetime.datetime.now() - begin_time)
EDIT** Added a insert() line after the transpose to add back in the date column per per Ezer K suggestion and that seems to have solved it.
df.columns = ["Field",date.group(0)]
df.set_index("Field",inplace=True)
df_t = df.transpose()
df_t.insert(0, "Date:", date.group(0))
CodePudding user response:
It is hard to say exactly since your examples are hard to reproduce, but it seems that instead of adding a field you are changing the column names. try switching these rows in your function:
df.columns = ["Field",date.group(0)]
df.set_index("Field",inplace=True)
df_t = df.transpose()
with these:
df_t = df.transpose()
df_t.insert(0, "Date:", date.group(0))