The create clustered index index name on the name of the table (field name) building clustered index
Each table can have only one clustered index, because there is only one real physical structure, and SQL Server default a clustered index is built on the primary key, the biggest advantage is to reduce the query range, avoid full scan, whether often use clustered index or other columns, leading column must be the most frequently used column,
Using a clustered index is faster than using non clustered index keys, faster than made the order by the primary key of the commonly, especially the small data quantity, too many fragments of the index is easy to cause index,
Or will cause a full scan in
Index is the basis of the data structure of B + tree,
1 n KeZi node of the tree contains n keywords, do not save the data, save the data index
2 all the leaf node contains the key information, and a pointer to the records contain the keywords, and the leaf node itself according to the key size order connection
3 all the end nodes were classified as the index part, nodes only contains his son in the tree in the maximum or minimum keyword
Sparse index and dense index
Clustered index is sparse index, leaf node point to data page, non clustered index is high density index, leaf nodes to the data bank, internal node point to the index page, a leaf node for each data line stores a key/value pair
Indexes cover: SQL fields involved within the scope of the compound contained non clustered index, due to non clustered index leaf node, containing all the data row index value, the use of these nodes return true data
Dense index: file every search has a code value index, index entries including search code values and point to the search code value of the first data record pointer
Single index and composite index - according to the number of index field
Composite index, for example: the alter table myindex add index name_city_age (name, city, age)
mysql index type
The primary key index: special unique index, are not allowed to empty, general building table at the same time build primary key index
Normal index: the create index INDEX_NAME on table name (field name), to support the prefix index, general name can't more than 20 characters, so limit length of 20, can save the index file size
The only index: similar to ordinary index, but the value of the index columns must be unique, allowed to empty, if is a composite index, means that the combination must be the only such as the create index index_email on user (email);
Full-text index: FULLTEXT indexing, can only be used for myisam tables;
Composite INDEX: "the most left prefix" such as create table test (INT the NOT NULL, LASTNAME VARCHAR (20) FIRSTNAME VARCHAR (20), the INDEX NAME (LASTNAME, FIRSTNAME));
Can only be used to query the select * from test where lastname=""; Or select * from test where lastname="and" firstname="";
Cannot be used to select * from test where firstname="";
mysql myisam engine and the difference between the innodb engine
Myisam storage into three files on disk, the file name and the name of the table is the same, the extension respectively. FRM (storage table definition), the myd (storage database), the myi index (storage), data files, and index files can be placed in different directories, average distribution of IO, get faster, not limit in storage size, maximum effective mysql database table size is usually determined by the operating system restrictions on file size,
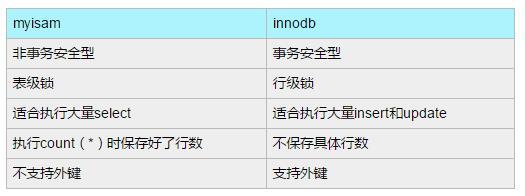
why myisam is faster than the innodb query speed
Innodb when do select to maintain more
Innodb to cache data block, myisam cache index blocks only
Innodb addressing is mapped to the first block, and then to line, myisam record directly is the file offset, positioning is faster than the innodb
Innodb to maintain multi version concurrency control
why use on the column as the primary key
If we define the primary key, innodb will select primary key as a clustered index, if not explicitly define a primary key, innodb will choose the first not only contains a NULL value index as the primary key index, if not, will choose within 6 bytes long rowid as implicit clustered index,
Data record itself is stored in the main index of leaf nodes, whenever there is a new record into the mysql will according to its primary key node and insert it into the appropriate position, if the page to load factor, the create a new page (nodes)
why use data index can improve efficiency
Data storage is orderly index
The orderly situation, through the index query do not need to traverse index record when a data
In extreme cases, the data index to converge with the query efficiency of LGN
what circumstance should be built or less indexed
Too little table record
Often insert, delete, modify the table
Data duplication and distribution of average table fields, if there is A table with 100000 rows, there is A field in A only T, F two kinds of values, each value distribution probability is about 50%, so to build A index will improve the query speed
Often a query, and the main field index value is more, but the main field in table fields
hash index and B + index
If the equivalent query, hash index obviously has absolute advantage, because need only one algorithm can find the corresponding keys, premise is the key value is the only, if not the only, you need to find key position first, and then according to the chain table scan back, until the corresponding data
If scope retrieval query, then use a hash index, had ordered the key value after hashing algorithm, may not even
Hash index page can't, use index finished sorting, fuzzy query and the like '%' XXX
A hash index also does not support multiple columns combined index of the left matching rules
In the case of a large number of duplicate key values, a hash index efficiency is extremely low, exist the hash collision
The check of B + average efficiency, passive margin small
ACID
Atomicity (Atomicity)
Transaction is regarded as an integral unit, all the operations either all submitted successfully, or all rolled back, failure rollback can use log, logging the firm to perform modification operations, it reverses the modification operations when the rollback
Consistency (Consistency)
Database consistency condition before and after the transaction execution, in the condition of consistency, all transactions with the result of a data read the same
Isolation (Isolation)
A firm changes before the final submission is not visible to other transactions
Durability (Durability)
Once the transaction commits, the changes will be saved to the database, even if the system crashes, the results of the transaction cannot be lost, can be done by the database backup and recovery, when the system crashes, using backup of the database for data recovery,
Relationship between
Only satisfy consistency, transaction execution result is right, in the case of no concurrent, serial execution, transaction isolation will be able to meet, at this time as long as can satisfy the atomicity, we will be able to satisfy the consistency; In concurrent cases, multiple transactions executed, should not only meet the atomicity, but also satisfy the isolation, satisfying consistency, transaction meet the persistence is in order to cope with the database of collapse
blockade
Mysql provides two kinds of block size:
Row-level locks and table level lock, lock should try to only need to modify the part of the data, not all resources, locking the less amount of data, the smaller the possibility of lock contention, the higher the degree of concurrent systems, but the lock need to consume resources, lock the various operations (including locks, lock is released, and check the lock state) can increase system overhead, thus blocking the smaller particle size, the larger the system overhead
The advantages and disadvantages of row-level locking
Advantages:
When in many threads access different rows, there is only a small amount of locking conflicts
Rolled back when only a small amount of change
Long time to lock in a single line
Disadvantages:
Levels than page or table lock takes up more memory
When used in much of the table, is slower than the page level or table level lock
If on the most regular GROUP BY operation or must constantly scanning the entire table, slower than other lock
With high level locking, through support for different types of lock, you can easily adjust the application, because the lock cost less than row-level locking
Block type:
1 read-write lock
Exclusive lock (Exclusive), abbreviated as an X lock, also known as write locks
A Shared lock (Shared), referred to as S lock, lock is also called read
Regulation: A transaction for A data object X lock, can read and update of A lock during other matters not of any lock A
A transaction for A data object S lock, it can be read on A operation, but can't update operation, the other matters during the lock to A S, but cannot add X lock,
2 intent locks
Use intention can be easier to support multiple granularity lock blockade,
In the presence of row-level locks and table level lock, plus X transaction T want to list A lock, you need to detect whether there are other issues on the table or A table of arbitrary line with A lock, it needs to be on the table A, each line detection time, this is very time consuming
Intent locks in the original X, S lock introduced IX/IS, they are all table locks, used to indicate a transaction to add X lock at a row in a table or S lock, has the following two requirements:
A transaction before get a data line object S lock, must first gain table IS locked or stronger
A transaction in a data row objects X lock before, must first get a table IX lock
Any IS/are compatible between IX, because they just said want to lock table, rather than a true lock
S and S only lock locks, lock IS compatible, that IS to say, the transaction T want to expert S lock data, other transactions can get on the table or in the table already done S lock
The blockade agreement
1 level 3 blockade agreement
Level blockade protocol: transaction T to modify the data A, must add X lock, until the end of the T to release the lock, can solve the problem of missing modification, because they cannot afford to have two issues to modify the same data at the same time, the transaction of sexy won't be overwritten
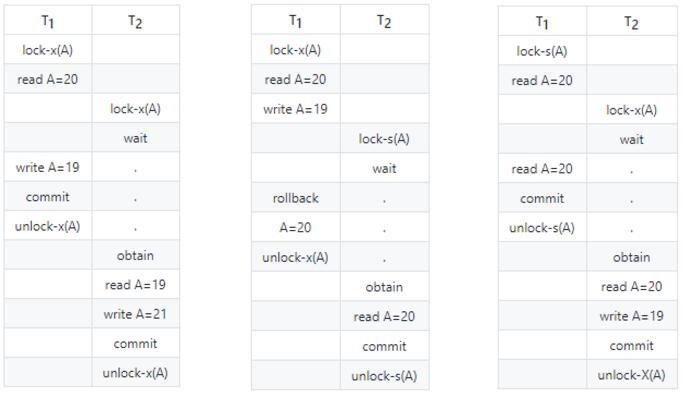
Secondary blockade agreement: on the basis of the level, to read A must add S locked, read the release S lock immediately, can solve the problem of reading dirty data, because if A transaction on A modified data, according to the level 1 blockade, will add X lock, so can't add S lock, also is not read in the data
Level 3 blockade agreement: on the basis of the secondary, to read A must add S locked, until the end of the transaction to the release of the S lock, can solve the problem of not repeatable read, because reading A, other issues not to add A X lock, avoiding the reading data during the period of change
Two locking protocol
Locking and unlocking is divided into two stages, and serializable schedule means, through the concurrency control, the transaction result of concurrent execution serial execution with a transaction results, the same transaction follow two locking protocol is guarantee the sufficient conditions of serializable schedule, such as the operation meet two paragraphs lock protocol, it is serializable schedule
The lock - x (A)... The lock - s (B)... The lock - s (C)... Unlock (A)... Unlock (C)... Unlock (B)
But not necessary condition, for example, the following does not meet the two lock protocol, but still serializable schedule,
The lock - x (A)... Unlock (A)... The lock - s (B)... Unlock (B)... The lock - s (C)... Unlock (C)
Mysql implicit and display lock
nullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull