Let's say I have the following dataframe which is sorted for ease visually:

How would I utilize window functions to create a new column that sums the previous row ordered by Month column within each period partition:
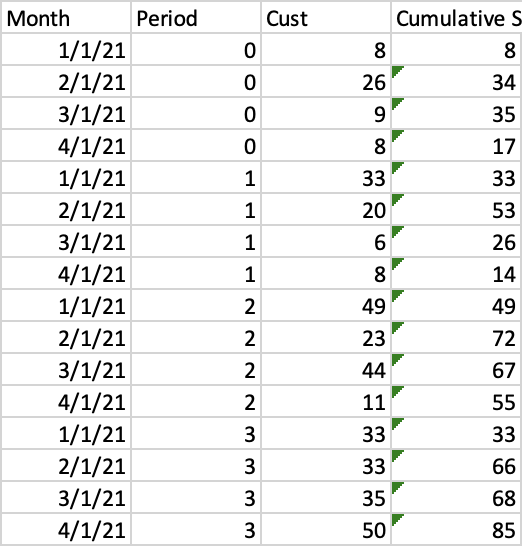
The following is my attempt at it, but I'm obviously doing something wrong with respect to the rowsBetween function.
df = df.withColumn('CustLast2', sum('Cust').over(Window.partitionBy("period").orderBy('Month').rowsBetween(Window.currentRow, -1))
CodePudding user response:
What you want is to sum the last 2 rows (current row included), so simply specify the rowsBetween like this:
from pyspark.sql import functions as F, Window
w = Window.partitionBy('Period').orderBy('Month').rowsBetween(-1, Window.currentRow)
df = df.withColumn('CustLast2', F.sum('Cust').over(w))
You inverted the lower and upper bounds of the window frame in your attempt.
CodePudding user response:
We made the Fugue project to port native Python or Pandas code to Spark or Dask. This lets you can keep the logic very readable by expressing it in native Python. Fugue can then port it to Spark for you with one function call.
First we start with a test Pandas DataFrame (we'll port to Spark later):
import pandas as pd
df = pd.DataFrame({"date": ["2020-01-01", "2020-01-02", "2020-01-03"] * 3,
"period": [0,0,0,1,1,1,2,2,2],
"val": [4,5,2] * 3})
Then we make a Pandas based function. Notice this is meant to be applied per group. We will partition later.
def rolling(df: pd.DataFrame) -> pd.DataFrame:
df["cum_sum"] = df["val"].rolling(2).sum().fillna(df["val"])
return df
Now we can use the Fugue transform function to test on Pandas. This function handles the partition and presort also.
from fugue import transform
transform(df, rolling, schema="*, cum_sum:float", partition={"by":"period", "presort": "date asc"})
Because this works, we can bring it to Spark just by specifying the engine:
import fugue_spark
transform(df, rolling, schema="*, cum_sum:float", partition={"by":"period", "presort": "date asc"}, engine="spark").show()
---------- ------ --- -------
| date|period|val|cum_sum|
---------- ------ --- -------
|2020-01-01| 0| 4| 4.0|
|2020-01-02| 0| 5| 9.0|
|2020-01-03| 0| 2| 7.0|
|2020-01-01| 1| 4| 4.0|
|2020-01-02| 1| 5| 9.0|
|2020-01-03| 1| 2| 7.0|
|2020-01-01| 2| 4| 4.0|
|2020-01-02| 2| 5| 9.0|
|2020-01-03| 2| 2| 7.0|
---------- ------ --- -------
Notice you need .show() now because of Spark's lazy evaluation. The Fugue transform function can take in both Pandas and Spark DataFrames and will output
CodePudding user response:
You can solve this problem using the code below:
(df.withColumn('last_value', F.lag(F.col('Cust')).over(W.partitionBy(['Period']).orderBy(F.col('Month'))))
.withColumn('last_value', F.when(F.col('last_value').isNull(), 0).otherwise(F.col('last_value')))
.withColumn('cumSum', F.col('Cust') F.col('last_value')))
CodePudding user response:
I think you're almost their, you just have to replace -1 by Window.unboundedPreceding
df = df.withColumn('CustLast2', sum('Cust').over(Window.partitionBy("period").orderBy('Month').rowsBetween(Window.unboundedPreceding, Window.currentRow))
Otherwise you're just doing the sum on 2 consecutive rows within the same period.