I am trying to iterate/loop a sum across multiple non-consecutive columns. My objective is to compute the subscale score of multiple questionnaires measured repeatedly across time.
Dataset for one questionnaire of x items and n time-points:
df <- tibble(
ID = 1:5,
itemA_1 = sample(100, 5, TRUE),
itemB_1 = sample(100, 5, TRUE),
itemC_1 = sample(100, 5, TRUE),
itemD_1 = sample(100, 5, TRUE),
itemx_1 = sample(100, 5, TRUE),
itemA_3 = sample(100, 5, TRUE),
itemB_3 = sample(100, 5, TRUE),
itemC_3 = sample(100, 5, TRUE),
itemD_3 = sample(100, 5, TRUE),
itemx_3 = sample(100, 5, TRUE),
itemA_n = sample(100, 5, TRUE),
itemB_n = sample(100, 5, TRUE),
itemC_n = sample(100, 5, TRUE),
itemD_n = sample(100, 5, TRUE),
itemx_n = sample(100, 5, TRUE),
)
The sum for one specific time point works just fine:
df %>% mutate(total_1 = sum(c(itemA_1, itemC_1, itemD_1))
This loop does not work:
for (i in c(1, 3, n)) {
df %>% mutate(total_i = sum(c(itemA_i, itemC_i, itemD_i))
}
What am I doing wrong?
CodePudding user response:
We may reshape to 'long' format with pivot_longer and do a group by sum
library(dplyr)
library(tidyr)
df1 <- df %>%
pivot_longer(cols =-ID, names_to = c("item", ".value"), names_sep = "_") %>%
filter(item %in% c("itemA", "itemC", "itemD")) %>%
group_by(ID) %>%
summarise(across(where(is.numeric), sum, na.rm = TRUE,
.names = "total_{.col}")) %>%
left_join(df, .)
-output
> df1
# A tibble: 5 × 19
ID itemA_1 itemB_1 itemC_1 itemD_1 itemx_1 itemA_3 itemB_3 itemC_3 itemD_3 itemx_3 itemA_n itemB_n itemC_n itemD_n itemx_n total_1
<int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 1 69 27 56 44 54 53 66 28 67 19 65 38 12 45 33 250
2 2 31 65 7 34 84 19 64 70 27 23 98 65 94 71 100 221
3 3 58 34 68 18 69 100 24 47 54 60 47 48 81 61 22 247
4 4 95 16 85 34 9 28 73 57 79 60 57 31 16 24 84 239
5 5 19 66 43 25 35 31 39 17 15 84 10 23 100 6 74 188
# … with 2 more variables: total_3 <int>, total_n <int>
If we want to use the for loop, then paste the column names with i, evaluate (!!) while assigning (:=)
library(stringr)
for (i in c(1, 3, 'n')) {
df <- df %>%
mutate(!! str_c("total_", i) :=
rowSums(across(all_of(str_c(c("itemA_", "itemC_", "itemD_"), i)))))
}
But, note that this will not be dynamic as we have to manually include the 1, 2, ..., n in the loop
-checking the output from for loop and reshaping
> all.equal(df1$total_1, df$total_1)
[1] TRUE
> all.equal(df1$total_3, df$total_3)
[1] TRUE
> all.equal(df1$total_n, df$total_n)
[1] TRUE
CodePudding user response:
Here's a base R option without pivoting, where we first select the columns that we want to sum, then get the unique suffix names, then we can use rowSums to get the sum of each group (i.e., each unique suffix). Then, I update the column names, and then merge with the original dataframe.
df_sum <- df[, grepl( "ID|itemA|itemC|itemD", names(df))]
suffixes <- unique(sub("^[^_]*_", "", colnames(df_sum)))
df2 <- sapply(suffixes, function(x) rowSums(df_sum[,endsWith(colnames(df_sum), x)]))
colnames(df2)[-1] <- paste("total", colnames(df2)[-1], sep = "_")
merge(x = df, y = df2, by = "ID", all.x = TRUE)
Output
ID itemA_1 itemB_1 itemC_1 itemD_1 itemx_1 itemA_3 itemB_3 itemC_3 itemD_3 itemx_3 itemA_n itemB_n itemC_n itemD_n itemx_n total_1 total_3 total_n
1 1 92 84 31 74 77 26 71 92 59 70 47 54 7 6 95 197 177 60
2 2 49 6 40 6 94 61 69 58 49 62 66 13 94 52 23 95 168 212
3 3 67 69 34 56 44 94 69 1 52 96 62 64 34 78 67 157 147 174
4 4 86 33 85 87 30 33 26 15 70 97 34 36 74 58 87 258 118 166
5 5 49 25 23 56 63 4 84 35 92 34 33 62 95 77 50 128 131 205
Data
df <- structure(list(ID = 1:5, itemA_1 = c(92L, 49L, 67L, 86L, 49L),
itemB_1 = c(84L, 6L, 69L, 33L, 25L), itemC_1 = c(31L, 40L,
34L, 85L, 23L), itemD_1 = c(74L, 6L, 56L, 87L, 56L), itemx_1 = c(77L,
94L, 44L, 30L, 63L), itemA_3 = c(26L, 61L, 94L, 33L, 4L),
itemB_3 = c(71L, 69L, 69L, 26L, 84L), itemC_3 = c(92L, 58L,
1L, 15L, 35L), itemD_3 = c(59L, 49L, 52L, 70L, 92L), itemx_3 = c(70L,
62L, 96L, 97L, 34L), itemA_n = c(47L, 66L, 62L, 34L, 33L),
itemB_n = c(54L, 13L, 64L, 36L, 62L), itemC_n = c(7L, 94L,
34L, 74L, 95L), itemD_n = c(6L, 52L, 78L, 58L, 77L), itemx_n = c(95L,
23L, 67L, 87L, 50L)), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -5L))
Benchmark
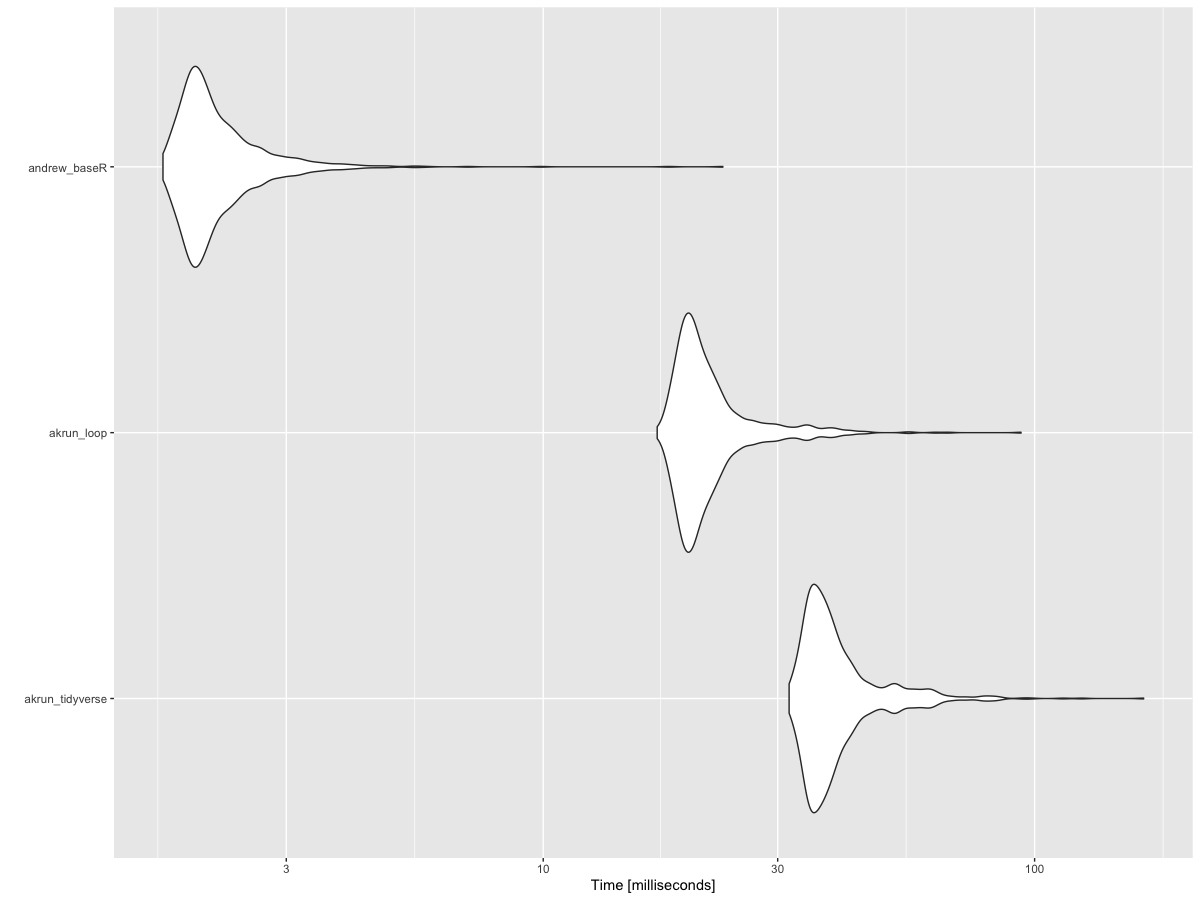
df1 <- df
df2 <- df
bm <- microbenchmark::microbenchmark(akrun_tidyverse = {df %>%
pivot_longer(cols =-ID, names_to = c("item", ".value"), names_sep = "_") %>%
filter(item %in% c("itemA", "itemC", "itemD")) %>%
group_by(ID) %>%
summarise(across(where(is.numeric), sum, na.rm = TRUE,
.names = "total_{.col}")) %>%
left_join(df, .)},
akrun_loop = {for (i in c(1, 3, 'n')) {
df1 <- df1 %>%
mutate(!! str_c("total_", i) :=
rowSums(across(all_of(str_c(c("itemA_", "itemC_", "itemD_"), i)))))
}},
andrew_baseR = {df_sum <- df2[, grepl( "ID|itemA|itemC|itemD", names(df2))];
suffixes <- unique(sub("^[^_]*_", "", colnames(df_sum)));
df3 <- sapply(suffixes, function(x) rowSums(df_sum[,endsWith(colnames(df_sum), x)]));
colnames(df3)[-1] <- paste("total", colnames(df3)[-1], sep = "_");
merge(x = df, y = df3, by = "ID", all.x = TRUE)},
times = 1000)
autoplot(bm)