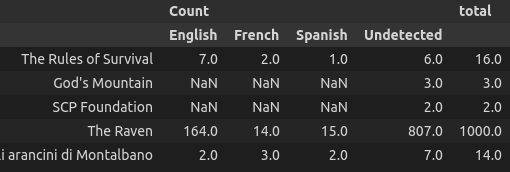
I did a groupby and sum on my df, and now it looks like this:
Count Count Count Count
God's Mountain
LANG English French Spanish
SCP Foundation 0,0,0
The Rules of Survival 7.0 2.0 1.0
Title 0,0,0
Formatted:
{('Count', ' English '): {'The Rules of Survival': 7.0, "God's Mountain": nan, 'SCP Foundation': nan, 'The Raven': 164.0, 'Gli arancini di Montalbano': 2.0}, ('Count', ' French '): {'The Rules of Survival': 2.0, "God's Mountain": nan, 'SCP Foundation': nan, 'The Raven': 14.0, 'Gli arancini di Montalbano': 3.0}, ('Count', ' Spanish '): {'The Rules of Survival': 1.0, "God's Mountain": nan, 'SCP Foundation': nan, 'The Raven': 15.0, 'Gli arancini di Montalbano': 2.0}, ('Count', 'Undetected'): {'The Rules of Survival': 6.0, "God's Mountain": 3.0, 'SCP Foundation': 2.0, 'The Raven': 807.0, 'Gli arancini di Montalbano': 7.0} }
I would like to add a Total column, so that I would get
LANG English French Spanish, Total
SCP Foundation 0,0,0, 0
The Rules of Survival 7.0 2.0 1.0, 10.0
Title 0,0,0, 0
This is the whole code:
d2 = d2.groupby(['Title', 'LANG'], sort=False).sum().unstack()
d2.loc['Column_Total'] = d2.sum(numeric_only=True, axis=0)
print(d2['Column_Total'])
When I print it, it looks the same because the names of the column are a bit skewed I think, or I don't have other explanations
CodePudding user response:
As I understand, you want to add a new column with total values. So this might help you:
d2['','Column_Total'] = d2.sum(numeric_only=True, axis=1)
Or if you do not use multiindex at columns just
d2['Column_Total']= d2.sum(axis=1)
CodePudding user response:
Your dataframe looks weird but I guess you want an additional Column with the total? So starting from:
import pandas as pd
import numpy as np
data = {('Count', ' English '): {'The Rules of Survival': 7.0, "God's Mountain": np.nan, 'SCP Foundation': np.nan, 'The Raven': 164.0, 'Gli arancini di Montalbano': 2.0}, ('Count', ' French '): {'The Rules of Survival': 2.0, "God's Mountain": np.nan, 'SCP Foundation': np.nan, 'The Raven': 14.0, 'Gli arancini di Montalbano': 3.0}, ('Count', ' Spanish '): {'The Rules of Survival': 1.0, "God's Mountain": np.nan, 'SCP Foundation': np.nan, 'The Raven': 15.0, 'Gli arancini di Montalbano': 2.0}, ('Count', 'Undetected'): {'The Rules of Survival': 6.0, "God's Mountain": 3.0, 'SCP Foundation': 2.0, 'The Raven': 807.0, 'Gli arancini di Montalbano': 7.0} }
df1 = pd.DataFrame(data)
df1
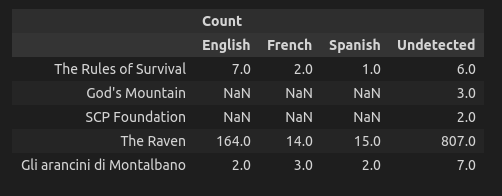
The Solution might be simply do it like this :
df1['total']=df1.sum(axis=1)
df1