I am trying to aggregate and count values together. Below you can see my dataset
data = {'id':['1','2','3','4','5'],
'name': ['Company1', 'Company1', 'Company3', 'Company3', 'Company5'],
'sales': [10, 3, 5, 1, 0],
'income': [10, 3, 5, 1, 0],
}
df = pd.DataFrame(data, columns = ['id','name', 'sales','income'])
conditions = [
(df['sales'] < 1),
(df['sales'] >= 1) & (df['sales'] < 3),
(df['sales'] >= 3) & (df['sales'] < 5),
(df['sales'] >= 5)
]
values = ['<1', '1-3', '3-5', '>= 5']
df['range'] = np.select(conditions, values)
df=df.groupby('range')['sales','income'].agg(['count','sum']).reset_index()
This code gives me the next table
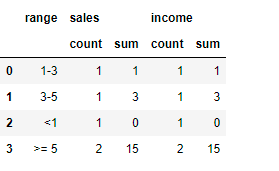
But I am not satisfied with the appearance of this table because 'count' is duplicated two times. So can anybody help me with this table in order to have separate columns 'range', 'count', 'income' and 'sales'.
CodePudding user response:
You could try named aggregation:
df.groupby('range', as_index=False).agg(count=('range','count'), sales=('sales','sum'), income=('income','sum'))
Output:
range count sales income
0 1-3 1 1 1
1 3-5 1 3 3
2 <1 1 0 0
3 >= 5 2 15 15
P.S. You probably want to make "range" a categorical variable, so that the output is sorted in the correct order:
df['range'] = pd.Categorical(np.select(conditions, values), categories=values, ordered=True)
Then the above code outputs:
range count sales income
0 <1 1 0 0
1 1-3 1 1 1
2 3-5 1 3 3
3 >= 5 2 15 15