I am merging several sizeable dataframes:
path ='D:/filename.csv'
dfa=pd.read_csv(path, header=0, delimiter=',',encoding='latin-1', dtype=str)
dfa=dfa.rename(columns={"ybvd": "yBvD"})
df=df.merge( dfa, on=['yBvD'], copy=True, how='left')
I am getting the following error:
MemoryError: Unable to allocate 11.8 GiB for an array with shape (1577604547,) and data type int64
I don't quite understand why, especially since it doesn't happen for the same merging process each time (I merge several datasets, the code is representative of what I use each time). At no point does the code use more than 60% of my RAM (256GB total RAM capacity). I also have 800GB in virtual memory left. There is plenty of space on the hard disk I want to write the files to.
I am therefore not quite sure what this error is supposed to indicate to me or how to resolve it.
CodePudding user response:
MemoryError: Unable to allocate 11.8 GiB for an array with shape (1577604547,) and data type int64
This mean you do not have enough free space in RAM.
At no point does the code use more than 60% of my RAM
pandas is saying it does need 11.8 GiB, please consider not how many % of RAM is used, but how many GiB is still free.
how to resolve it.
If you are unable to secure enough RAM space then you would find way to do your operation without loading data all at once, see 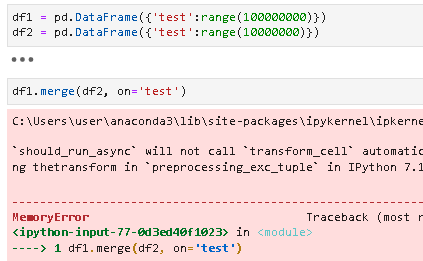
and using batching approach:
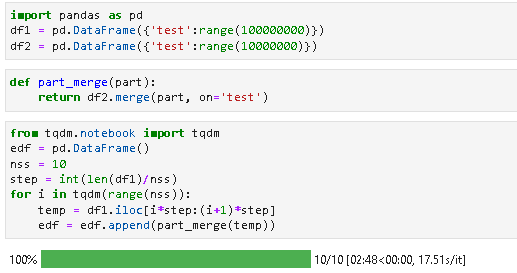
Code:
from tqdm.notebook import tqdm
def part_merge(part):
return df2.merge(part, on='test')
edf = pd.DataFrame()
nss = 10
step = int(len(df1)/nss)
for i in tqdm(range(nss)):
temp = df1.iloc[i*step:(i 1)*step]
edf = edf.append(part_merge(temp))