I have a huge df that looks like this:
| date | stock1 | stock2 | stock3 | stock4 | stock5 | stock6 | stock7 | stock8 | stock9 | stock10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 10/20 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.9 |
| 11/20 | 0.8 | 0.9 | 0.3 | 0.4 | 0.3 | 0.5 | 0.3 | 0.2 | 0.4 | 0.1 |
| 12/20 | 0.3 | 0.6 | 0.9 | 0.5 | 0.6 | 0.7 | 0.8 | 0.7 | 0.9 | 0.1 |
I want to find, for each row, the 20% higher values of stocks and the 20% lower. The output should be:
| date | higher | lower |
|---|---|---|
| 10/20 | stock9, stock 10 | stock1, stock 2 |
| 11/20 | stock1, stock 2 | stock8, stock 10 |
| 12/20 | stock3, stock 9 | stock1, stock 10 |
My code looks now like this:
l= df.count(1)
rank = pd.DataFrame()
for i in len(l):
rank[i, "winners"] = df.apply(lambda x: x.nlargest(round(l[i-1]*0.2).index.tolist(), axis=1)
rank[i, "losers"] = df.apply(lambda x: x.nsmallest(round(l[i-1]*0.2).index.tolist(), axis=1)
and I get the error "TypeError: 'int' object is not callable". I have checked the dtype of l: Freq: M, Length: 344, dtype: float64. What can I be doing wrong?
CodePudding user response:
Use:
df = pd.DataFrame({'stock1':range(10), 'stock2':range(10,20), 'stock3':range(10,20), 'stock4':range(10,20), 'stock5':range(50,60)})
colnum = int(.2*len(df.columns))
df.apply(lambda x: x.nlargest(colnum).index.tolist(), axis=1)
input df:
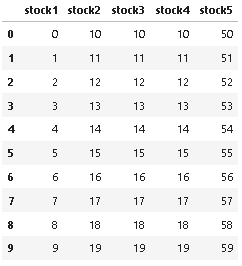
output:

Based on your comment:
df = pd.DataFrame({f'stock{i}':np.random.randint(1,10,10) for i in range(2000)})
colnum = int(.2*len(df.columns))
df.apply(lambda x: x.nlargest(colnum).index.tolist(), axis=1)
input df with 2000 columns:
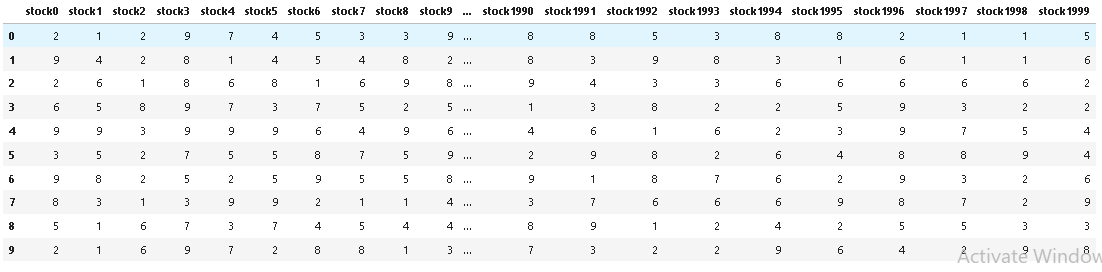
output:

Based on the other comment, with possible nans:
df = pd.DataFrame({f'stock{i}':np.random.randint(1,10,10) for i in
range(10)})
df2 = pd.DataFrame({f'stock{i}':np.random.randint(1,10,1) for i in range(7)})
df3 = df.append(df2)
df3 = df3.astype(np.float64)
df3.apply(lambda x: x.nlargest(int(.2*np.sum([1 for y in x if not np.isnan(y)]))).index.tolist(), axis=1)
input df:
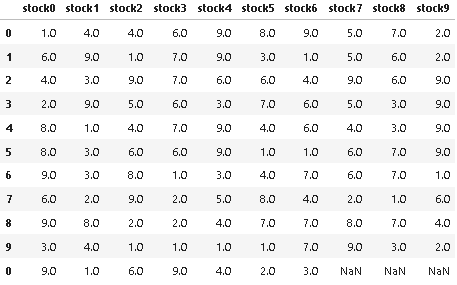
output:

a little bit better:
df3.apply(lambda x: x.nlargest(int(.2*x.notna().sum())).index.tolist(), axis=1)
CodePudding user response:
Use DataFrame.assign for new columns:
df1 = df.set_index('date')
i= int(round(len(df1.columns)*0.2))
df1 = df1.assign(winners = df1.apply(lambda x: x.nlargest(i).index.tolist(), axis=1),
losers = df1.apply(lambda x: x.nsmallest(i).index.tolist(), axis=1))
rank = df1[['winners','losers']].reset_index()
print (rank)
date winners losers
0 10/20 [stock9, stock10] [stock1, stock2]
1 11/20 [stock2, stock1] [stock10, stock8]
2 12/20 [stock3, stock9] [stock10, stock1]