I have a dataframe like as shown below
import numpy as np
import pandas as pd
from numpy.random import default_rng
rng = default_rng(100)
cdf = pd.DataFrame({'Id':[1,2,3,4,5],
'customer': rng.choice(list('ACD'),size=(5)),
'region': rng.choice(list('PQRS'),size=(5)),
'dumeel': rng.choice(list('QWER'),size=(5)),
'dumma': rng.choice((1234),size=(5)),
'target': rng.choice([0,1],size=(5))
})
I would like to do the below
a) extract the data for unique combination of region and customer. Meaning groupby.
b) store them in each sheet of one excel file (based on number of groups)
I was trying something like below but there should be some neat pythonic way to do this
df_list = []
grouped = cdf.groupby(['customer','region'])
for k,v in grouped:
for i in range(len(k)):
df = cdf[(cdf['customer']==k[i] & cdf['region']==k[i 1])]
df_list.append(df)
I expect my output to be like below (showing in multiple screenshots).
As my real data has 200 columns and million rows, any efficient and elegant approach would really be helpful
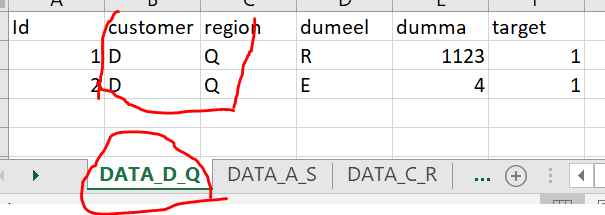
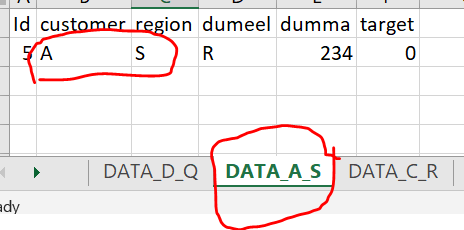
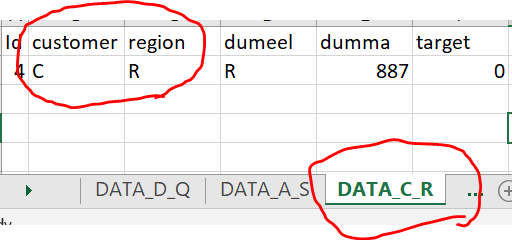
CodePudding user response:
Use this solution in loop:
writer = pd.ExcelWriter('out.xlsx', engine='xlsxwriter')
for (cust, reg), v in cdf.groupby(['customer','region']):
v.to_excel(writer, sheet_name=f"DATA_{cust}_{reg}")
# Close the Pandas Excel writer and output the Excel file.
writer.save()