I am working with the following web site: 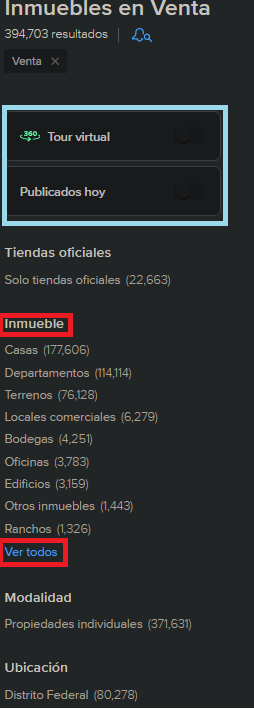
As shown in the image below, the classes ui-search-filter-dl contain the specific sections from the menu from above image; while ui-search-filter-container classes contain the sub-sections displayed by the site (e.g. Casas, Departamento & Terrenos for Inmueble). With the intention of obtaining the link from "ver todos" button from "Inmueble" section, I was using this line of code:
ver_todos = response.css('div.ui-search-filter-dl')[2].css('a.ui-search-modal__link').attrib['href']
But since "Tour virtual" and "Publicados hoy" are not always in the page, I cannot be sure that ui-search-filter-dl at index 2 is always the index corresponding to "ver todos" button.
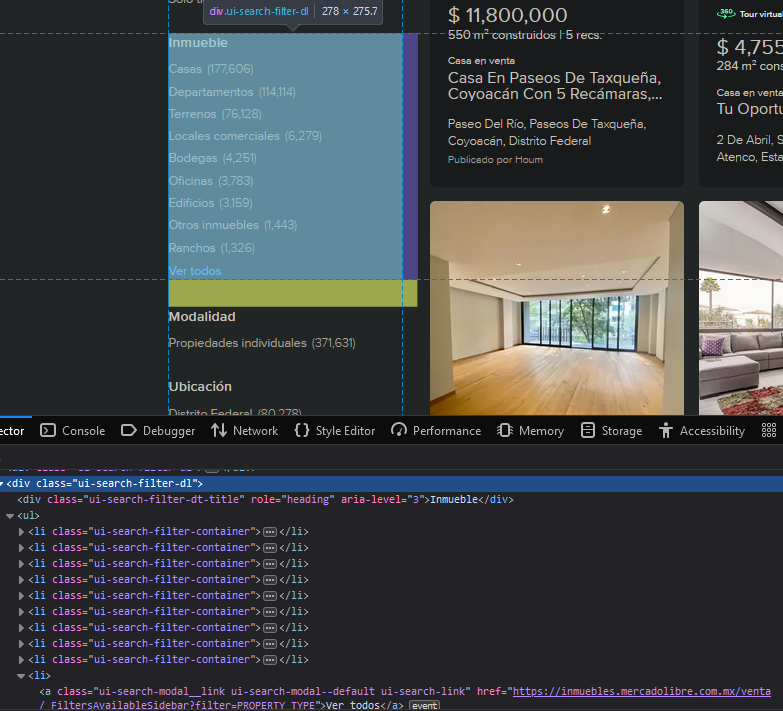
I was trying to get the link from "ver todos" by using this line of code:
response.css(''':contains("Inmueble") ~ .ui-search-filter-dt-title
.ui-search-modal__link::attr(href)''').extract()
Basically, I was trying to get the href from a ui-search-filter-dt-title class that contains the title "Inmueble". Unfortunately, the output is an empty list. I would like to find the link from "ver todos" by using css and regex but I'm having trouble with it. How may I achieve that?
CodePudding user response:
An easy way you could do it is by getting all the link <a> and then checking if any of their text matches ver todos.
import requests
from bs4 import BeautifulSoup
link = "https://inmuebles.mercadolibre.com.mx/venta/"
def main():
res = requests.get(link)
if res.status_code == 200:
soup = BeautifulSoup(res.text, "html.parser")
links = [a["href"] for a in soup.select("a") if a.text.strip().lower() == "ver todos"]
print(links)
if __name__ == "__main__":
main()
CodePudding user response:
I think xpath is easier to select the target elements in most cases:
Code:
xpath = "//div[contains(text(), 'Inmueble')]/following-sibling::ul//a[contains(@class,'ui-search-modal__link')]/@href"
url = response.xpath(xpath).extract()[0]
Actually, I didn't create a scrapy project to check your code. Alternatively, I implemented the following code:
from lxml import html
import requests
res = requests.get( "https://inmuebles.mercadolibre.com.mx/venta/")
dom = html.fromstring(res.text)
xpath = "//div[contains(text(), 'Inmueble')]/following-sibling::ul//a[contains(@class,'ui-search-modal__link')]/@href"
url = dom.xpath(xpath)[0]
assert url == 'https://inmuebles.mercadolibre.com.mx/venta/_FiltersAvailableSidebar?filter=PROPERTY_TYPE'
Since the xpath should be the same among scrapy and lxml, of course, I hope the code shown in the beginning will also work fine in your scrapy project.