Here my probleme :
Assuming this graph :
import networkx as nx
import pandas as pd
user_network_G = user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893])
nan_edge = [(u, v) for (u, v, d) in user_network_G.edges(data=True) if math.isnan(d["Trust"])]
real_edge = [(u, v) for (u, v, d) in user_network_G.edges(data=True) if math.isnan(d["Trust"]) == False]
pos = nx.kamada_kawai_layout(user_network_G)
# nodes
nx.draw_networkx_nodes(user_network_G, pos, node_size=700)
# edges
nx.draw_networkx_edges(user_network_G, pos, edgelist = real_edge, width=2)
nx.draw_networkx_edges(user_network_G, pos, edgelist = nan_edge, width=2, style="dashed")
# labels
nx.draw_networkx_labels(user_network_G, pos, font_size=12, font_family="sans-serif")
nx.draw_networkx_edge_labels(user_network_G, pos, edge_labels = nx.get_edge_attributes(user_network_G,'Trust') , font_size=10, font_family='sans-serif', label_pos = 0.6)
nx.draw_networkx_edge_labels(user_network_G, pos, edge_labels = nx.get_edge_attributes(user_network_G,'Intersection') , font_size=10, font_family='sans-serif', label_pos = 0.4)
plt.axis("off")
plt.show()
Giving :
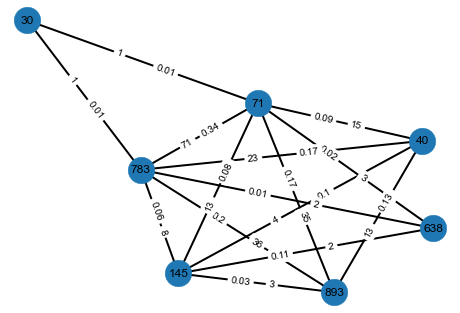
Where :
- The integers on the edges are the cardinality of products set in common between two users (the nodes)
- The decimals on the edges are the truth score between two nodes (i.e two users)
Now i want to compute the edge value of non existing edges between two nodes (for example between node 30 and node 40).
To achieve this i firstly create my graph (the one depicted above) :
user_trust_cardinality_network = nx.from_pandas_edgelist(user_local_trust_computation(normalized_user_rating_matrix)[1].reset_index(level = ['User_U','User_V']), 'User_U', 'User_V', ['Trust', 'Intersection', 'Pondered_Trust'])
#Creation of the graph from a table containing for each existing paire of nodes the Trust Score, the Cardinality and the Pondered_Trust_Score
user_trust_cardinality_network.remove_edges_from(nx.selfloop_edges(user_trust_cardinality_network))
#Remove selfloop edges
edges_to_predict = [(u, v) for (u, v, d) in user_trust_cardinality_network.edges(data=True) if math.isnan(d["Trust"]) == True]
#Storing the set of edges to predict (edges where trust is NaN)
edges_to_predict_sub = [(u, v) for (u, v, d) in user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]).edges(data=True) if math.isnan(d["Trust"]) == True]
#Edges to predict on my subgraph (for quick example computation)
user_trust_cardinality_network.remove_edges_from([(u, v) for (u, v, d) in user_trust_cardinality_network.edges(data=True) if math.isnan(d["Trust"]) == True])
#Remove edges to predict, to add them after with the newly computed score
Then i compute the score of the removed edges with :
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_dict = {}
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust_dict = {'Path%s' % [u,v] : sum(pondered_trust)/sum(intersection)}
print(short_path_trust_dict)
Giving me this :
short_path_trust(user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]), edges_to_predict_sub, 2)
{'Path[40, 30]': 0.08499999999999999}
{'Path[40, 30]': 0.16333333333333333}
{'Path[40, 638]': 0.07833333333333332}
{'Path[40, 638]': 0.10333333333333333}
{'Path[40, 638]': 0.1572}
{'Path[145, 30]': 0.075}
{'Path[145, 30]': 0.05444444444444444}
{'Path[30, 638]': 0.017499999999999998}
{'Path[30, 638]': 0.01}
{'Path[30, 893]': 0.16555555555555557}
{'Path[30, 893]': 0.19486486486486487}
{'Path[893, 638]': 0.1581578947368421}
{'Path[893, 638]': 0.062}
{'Path[893, 638]': 0.19}
My problem is that the result seems to be a dictionary generator, hence a set of independent dictionnaries. It's not a dictionary of dictionary (i already invegasting this possibility), here the proof :
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_dict = {}
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust_dict = {'Path%s' % [u,v] : sum(pondered_trust)/sum(intersection)}
print(type(short_path_trust_dict))
Return :
short_path_trust(user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]), edges_to_predict_sub, 2)
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
<class 'dict'>
Here is my main problem, if i call for creating a database :
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_dict = []
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust = [((u,v), sum(pondered_trust)/sum(intersection))]
short_path_trust_df = pd.DataFrame(short_path_trust, columns= ['Nodes','Path_Trust'])
print(short_path_trust_df)
I get :
short_path_trust(user_trust_cardinality_network.subgraph([30,40,71,145,638,783,893]), edges_to_predict_sub, 2)
Nodes Path_Trust
0 (40, 30) 0.085
Nodes Path_Trust
0 (40, 30) 0.163333
Nodes Path_Trust
0 (40, 638) 0.078333
Nodes Path_Trust
0 (40, 638) 0.103333
Nodes Path_Trust
0 (40, 638) 0.1572
Nodes Path_Trust
0 (145, 30) 0.075
Nodes Path_Trust
0 (145, 30) 0.054444
Nodes Path_Trust
0 (30, 638) 0.0175
Nodes Path_Trust
0 (30, 638) 0.01
Nodes Path_Trust
0 (30, 893) 0.165556
Nodes Path_Trust
0 (30, 893) 0.194865
Nodes Path_Trust
0 (893, 638) 0.158158
Nodes Path_Trust
0 (893, 638) 0.062
Nodes Path_Trust
0 (893, 638) 0.19
Yet, my goal is to get one DataFrame like this :
Nodes Path_Trust
0 (40, 30) 0.085
1 (40, 30) 0.163333
2 (40, 638) 0.078333
3 (40, 638) 0.103333
4 (40, 638) 0.1572
5 (145, 30) 0.075
6 (145, 30) 0.054444
7 (30, 638) 0.0175
8 (30, 638) 0.01
9 (30, 893) 0.165556
10 (30, 893) 0.194865
11 (893, 638) 0.158158
12 (893, 638) 0.062
13 (893, 638) 0.19
Or, better :
Node1 Node 2 Trust
0 40 30 0.085
1 40 30 0.163333
2 40 638 0.078333
3 40 638 0.103333
4 40 638 0.1572
5 145 30 0.075
6 145 30 0.054444
7 30 638 0.0175
8 30 638 0.01
9 30 893 0.165556
10 30 893 0.194865
11 893 638 0.158158
12 893 638 0.062
13 893 638 0.19
I hope i well explained my problem. If you need more informations i'll do my best to provide them. Thanks for helping :)
CodePudding user response:
In your code, you create a new dictionary for each node pair, that has the same name as the old dictionary, so you are overwriting your data. Even if you fixed that, you would run into the issue of having duplicate keys when you compare the same nodes.
Instead, I would recommend using a list, like so:
def short_path_trust (graph, edges_to_predict,cutoff) :
short_path_trust_list = []
for (u,v) in edges_to_predict :
for edges_path in nx.all_simple_edge_paths(graph, u, v, cutoff):
pondered_trust = [d['Pondered_Trust'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
intersection = [d['Intersection'] for (x,y,d) in graph.edges.data() if (x,y) in edges_path or (y,x) in edges_path]
short_path_trust_list.append([u,v, sum(pondered_trust)/sum(intersection)])
return pd.DataFrame(short_path_trust_list, columns=['node1', 'node2', 'trust'])
As a general thing, while your post is very detailed, I cannot reproduce your problem, because you did not define the graph you took a subgraph from.