I have a sample dataframe of a very huge dataframe as given below.
import pandas as pd
import numpy as np
NaN = np.nan
data = {'Start_x':['Tom', NaN, NaN, NaN,NaN],
'Start_y':[NaN, 'Nick', NaN, NaN, NaN],
'Start_z':[NaN, NaN, 'Alison', NaN, NaN],
'Start_a':[NaN, NaN, NaN, 'Mark',NaN],
'Start_b':[NaN, NaN, NaN, NaN, 'Oliver'],
'Sex': ['Male','Male','Female','Male','Male']}
df = pd.DataFrame(data)
df
I want the final result to look like the image given below. The 4 columns have to be merged to a single new column but the 'Sex' column should be as it is.
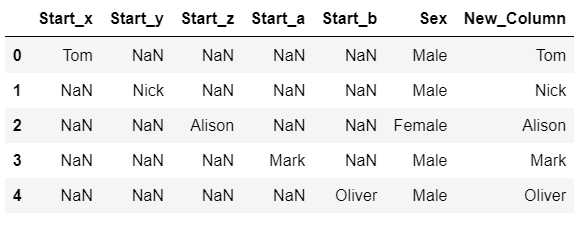
Any help is greatly appreciated. Thank you!
CodePudding user response:
One option could be to backfill Start columns by rows and then take the first column:
df['New_Column'] = df.filter(like='Start').bfill(axis=1).iloc[:, 0]
df
Start_x Start_y Start_z Start_a Start_b Sex New_Column
0 Tom NaN NaN NaN NaN Male Tom
1 NaN Nick NaN NaN NaN Male Nick
2 NaN NaN Alison NaN NaN Female Alison
3 NaN NaN NaN Mark NaN Male Mark
4 NaN NaN NaN NaN Oliver Male Oliver