I have a dataframe like as shown below
tdf = pd.DataFrame(
{'Unnamed: 0' : ['Region','Asean','Asean','Asean','Asean','Asean','Asean'],
'Unnamed: 1' : ['Name', 'DEF', 'GHI', 'JKL', 'MNO', 'PQR','STU'],
'2017Q1' : ['target_achieved',2345,5678,7890,1234,6789,5454],
'2017Q1' : ['target_set', 3000,6000,8000,1500,7000,5500],
'2017Q1' : ['score', 86, 55, 90, 65, 90, 87],
'2017Q2' : ['target_achieved',245,578,790,123,689,454],
'2017Q2' : ['target_set', 300,600,800,150,700,500],
'2017Q2' : ['score', 76, 45, 70, 55, 60, 77]})
As you can see that, my column names are duplicated.
Meaning, there are 3 columns (2017Q1 each and 2017Q2 each)
dataframe doesn't allow to have columns with duplicate names.
I tried the below to get my expected output
tdf.columns = tdf.iloc[0]v # but this still ignores the column with duplicate names
update
After reading the excel file, based on jezrael answer, I get the below display
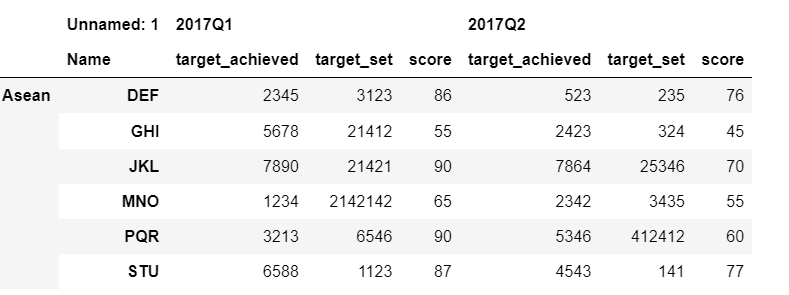
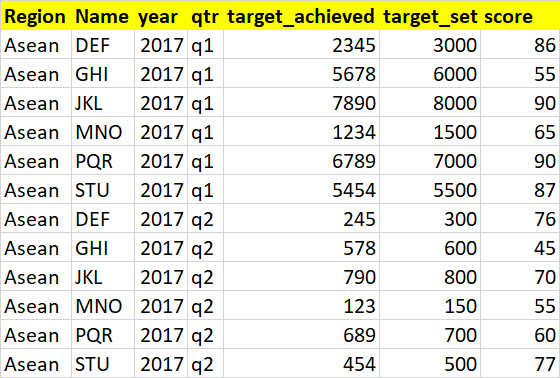
I expect my output to be like as shown below
CodePudding user response:
First create MultiIndex in columns and indices:
df = pd.read_excel(file, header=[0,1], index_col=[0,1])
If not possible, here is alternative from your sample data - converted columns and first row of data to MultiIndex in columns and first columns to MultiIndex in index:
tdf = pd.read_excel(file)
tdf.columns = pd.MultiIndex.from_arrays([tdf.columns, tdf.iloc[0]])
df = (tdf.iloc[1:]
.set_index(tdf.columns[:2].tolist())
.rename_axis(index=['Region','Name'], columns=['Year',None]))
print (df.index)
MultiIndex([('Asean', 'DEF'),
('Asean', 'GHI'),
('Asean', 'JKL'),
('Asean', 'MNO'),
('Asean', 'PQR'),
('Asean', 'STU')],
names=['Region', 'Name'])
print (df.columns)
MultiIndex([('2017Q1', 'target_achieved'),
('2017Q1', 'target_set'),
('2017Q1', 'score'),
('2017Q2', 'target_achieved'),
('2017Q2', 'target_set'),
('2017Q2', 'score')],
names=['Year', None])
And then reshape:
df1 = df.stack(0).reset_index()
print (df1)
Region Name Year score target_achieved target_set
0 Asean DEF 2017Q1 86 2345 3000
1 Asean DEF 2017Q2 76 245 300
2 Asean GHI 2017Q1 55 5678 6000
3 Asean GHI 2017Q2 45 578 600
4 Asean JKL 2017Q1 90 7890 8000
5 Asean JKL 2017Q2 70 790 800
6 Asean MNO 2017Q1 65 1234 1500
7 Asean MNO 2017Q2 55 123 150
8 Asean PQR 2017Q1 90 6789 7000
9 Asean PQR 2017Q2 60 689 700
10 Asean STU 2017Q1 87 5454 5500
11 Asean STU 2017Q2 77 454 500
EDIT: Solution for EDITed question is similar:
df = pd.read_excel(file, header=[0,1], index_col=[0,1])
df1 = df.rename_axis(index=['Region','Name'], columns=['Year',None]).stack(0).reset_index()