if a1_status, b1_status, c1_status, d1_status equal "Active" and a1, b1, c1, d1 equals "Loan" then output column "Loan_active" contains count of "Active" row wise. input dataframe looks like this.
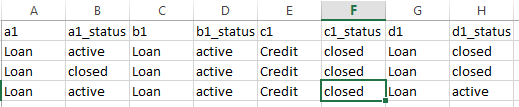
output dataframe :

use below code to create same dataframe mentioned above in image in pandas .
import pandas as pd
df = pd.DataFrame({'a1':['Loan','Loan','Loan'],
'a1_status' : ['active','closed','active'] ,
'b1' : ['Loan','Loan','Loan'],
'b1_status' : ['active','active','active'] ,
'c1' : ['Credit','Credit','Credit'],
'c1_status' : ['closed','closed','closed'] ,
'd1' : ['Loan','Loan','Loan'],
'd1_status' : ['closed','closed','active'] ,
})
print(df)
CodePudding user response:
Let us do shift
df['new'] = (df.eq('active') & df.shift(axis=1).eq('Loan')).sum(axis=1)
Out[349]:
0 2
1 1
2 3
dtype: int64
CodePudding user response:
This solution is not as elegant as the other, but it explictly select the columns that includes ONLY loans, then check their status. But this also assumes that the status columns will be named loan_status.
loan = df.columns[df.isin(["Loan"]).all()]
df['loan_active'] = df[loan "_status"].eq('active').sum(axis=1)
or if you prefer one liners;
df['loan_active'] = df[df.columns[df.isin(["Loan"]).all()] "_status"].eq('active').sum(axis=1)