I am trying to scrape IMDB top 250 movies using scrapy and stuck in finding the xpath for duration[I need to extract "2","h","44" and "m"] of each movie. Website link : https://www.imdb.com/title/tt15097216/?ref_=adv_li_tt
Here's the image of the HTML:
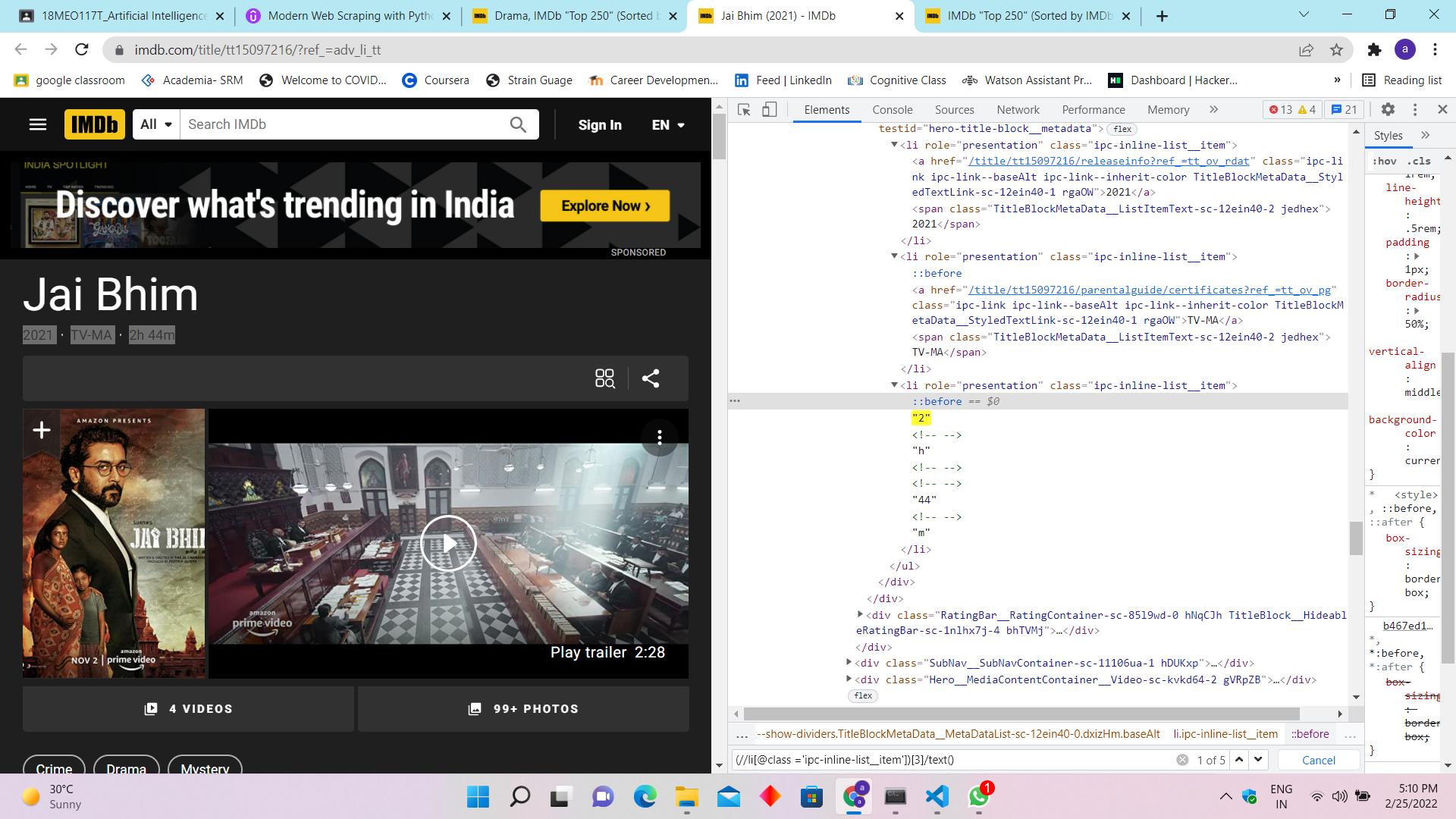
I've tried this Xpath but it's not accurate:
//li[@class ='ipc-inline-list__item']/following::li/text()CodePudding user response:
If it's always in the same position, what about:
//li[@class ='ipc-inline-list__item']/following::li[2]
or more simply:
//li[@class ='ipc-inline-list__item'][3]
or since the others have hyperlinks as the child, filter to just the li that has text() child nodes:
//li[@class ='ipc-inline-list__item'][text()]
However, the original XPath may be fine - it may be how you are consuming the information. If you are using .get() then try .getAll() instead.
CodePudding user response:
You can use this XPath to locate the element:
//span[contains(@class,'Runtime')]
To extract the text you can use this:
//span[contains(@class,'Runtime')]/text()